Loading...

GPT-5.3-Codex: Arquitectura Agéntica, "Auto-Debugging" y la Verdad Incómoda
Última actualización: 2/9/2026
GPT-5.3-Codex: Arquitectura Agéntica, "Auto-Debugging" y la Verdad Incómoda
Advertencia: Este no es otro artículo sobre "cómo usar ChatGPT". Vamos a destripar la arquitectura que está redefiniendo el desarrollo de software.
Olvídate de los chatbots tradicionales. Lo que OpenAI acaba de lanzar no es un "asistente" que responde preguntas triviales; es un empleado junior incansable capaz de trabajar en silencio, iterar y corregirse durante siete horas seguidas.
En el laboratorio hemos estado diseccionando GPT-5.3-Codex y la conclusión es brutal: estamos ante el fin de la "generación de código" estática y el inicio de la orquestación de desarrollo. Pero, como siempre en esta industria, el marketing esconde trade-offs ingenieriles masivos.
¿Un modelo que se depura a sí mismo? ¿Un riesgo de ciberseguridad clasificado como "Alto"?
Hoy abrimos el capó para enseñarte lo que realmente hay debajo.
⚡ TL;DR: Resumen Ejecutivo (Para el CTO con prisa)
Si solo tienes dos minutos, esto es lo que debes saber:
- Qué es: Un modelo agentic nativo. No solo escribe código; ejecuta terminales, corre tests y se corrige a sí mismo en bucles de larga duración.
- La Mejora Real: 77.3% en Terminal-Bench (dominio absoluto de CLI) vs una mejora más modesta en ingeniería de software pura.
- Infraestructura: Co-diseñado y entrenado en sistemas NVIDIA GB200 NVL72. Es un hardware lock-in de manual.
- El Riesgo: Clasificado como High capability en ciberseguridad bajo el Preparedness Framework. Puede automatizar gran parte de un ciberataque.
- Veredicto: Imprescindible para greenfield projects y scripts de infraestructura. Peligroso para arquitecturas legacy sin supervisión senior.
1. Deep Dive Técnico: La Mutación Arquitectónica
Aquí es donde la cosa se pone interesante para los ingenieros. El salto de GPT-5.2 a 5.3 no es cuestión de más parámetros, sino de densidad y estado.
Del "Stateless" al "Stateful Reasoning"
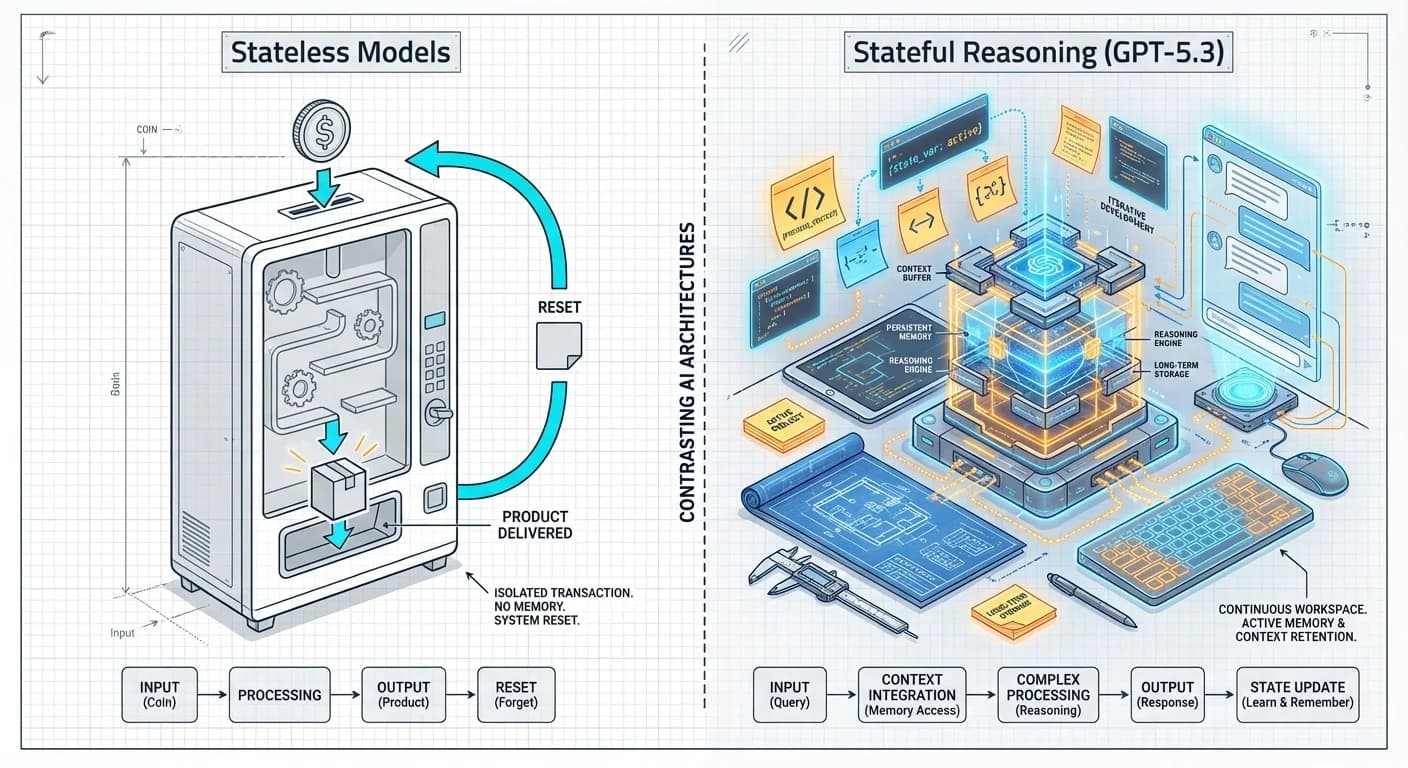
La gran mentira de los modelos anteriores era su amnesia. GPT-5.3-Codex introduce un mecanismo de preservación de estado entre llamadas a herramientas. Según la System Card oficial, combina el razonamiento de GPT-5.2 con capacidades de ejecución profunda.
Imagina este flujo de trabajo:
Cargando diagrama...
Lo revolucionario aquí es el nodo D (Bucle Agéntico). El modelo mantiene una representación interna del file system y los resultados de los tests. Esto explica por qué OpenAI reporta una eficiencia brutal en tareas largas: el modelo no re-ingiere todo el contexto, sino que opera sobre el estado actual del entorno.
Si te interesa profundizar en cómo los agentes mantienen el contexto, revisa nuestro análisis sobre Agent Chaining y Tool Use.
El Hardware Define el Software (El factor GB200)
OpenAI no solo entrenó el modelo en GPUs; diseñó el modelo para la arquitectura NVIDIA GB200 NVL72.
NVIDIA ha confirmado que este es el primer modelo agéntico que ayudó a construirse a sí mismo corriendo enteramente en estos sistemas. ¿Por qué importa esto?
- Memoria Compartida: Estos racks comparten memoria de una forma que permite gradientes más eficientes.
- Latencia: El resultado es un modelo hiper-optimizado para una topología de hardware específica.
⚠️ Nota técnica: Si intentas correr una versión destilada de esto en una H100 estándar, verás una degradación de latencia significativa.
2. Reality Check: Lo que se rompe en Producción
Nos encanta el hype, pero nos gustan más los datos. Hemos analizado los reportes técnicos y la letra pequeña de los benchmarks.
La Falacia del "25% Más Rápido"
OpenAI afirma que el modelo es un 25% más rápido para usuarios de Codex. La realidad: Es más rápido en promedio porque "piensa menos" en tareas fáciles. Pero en tareas complejas, la latencia es impredecible debido a su capacidad de pensamiento dinámico que puede durar desde segundos hasta horas.
El Modelo que se "Auto-Debuggeó" (Con asteriscos)
El titular "El modelo ayudó a crearse a sí mismo" es cierto, pero peligroso si se malinterpreta.
- Lo que hizo: Escribió regex para analizar logs, diagnosticó caídas en cache hit rates y optimizó el harness de entrenamiento.
- Lo que NO hizo: Inventar nuevas arquitecturas sin supervisión.
Fue un ingeniero junior brillante, no un arquitecto principal. Aún así, que el modelo sea capaz de diagnosticar por qué su propia infraestructura de serving es lenta es un hito de meta-automatización.
3. La Zona de Peligro: Ciberseguridad Dual
Aquí es donde los Managers deben prestar atención. GPT-5.3-Codex ha cruzado el umbral de seguridad. Para entender el contexto de estas amenazas, lee sobre la evolución de ataques cibernéticos.
- Capacidad Ofensiva: Es el primer modelo designado como High Capability para ciberseguridad. En simulaciones, puede identificar vulnerabilidades y explotarlas.
- Capacidad Defensiva: OpenAI ha lanzado el programa Trusted Access for Cyber para acelerar la investigación defensiva.
La barrera entre un agente de QA y un agente de pentesting es puramente una cuestión de prompting y permisos. Si le das acceso a tu terminal de producción, asume que tiene la capacidad técnica de un atacante competente.
4. Impacto de Negocio: ¿Vale la pena pagar?
ROI y Time-to-Market
- Startups & MVPs: El ROI es masivo. Un solo fundador técnico puede operar como un equipo pequeño usando el modelo para scaffolding, tests y documentación. Es ideal para fundadores solitarios.
- Enterprise Legacy: Cuidado. En bases de código antiguas (Java 8, COBOL), el modelo alucina más porque tiene menos data de entrenamiento de calidad en esos patrones arcaicos.
Competencia: ¿Claude o GPT?
La batalla es feroz. Según comparativas recientes:
| Característica | GPT-5.3-Codex | Claude Opus 4.6 |
|---|---|---|
| Uso de Terminal | ⭐⭐⭐⭐⭐ (77.3%) | ⭐⭐⭐ |
| Lógica Pura | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ (80.8%) |
| Infraestructura | Nativo | Requiere Tools |
Veredicto: Usa GPT-5.3 si necesitas DevOps y manejo de infraestructura. Usa Claude Opus si necesitas lógica pura de programación y resolución de bugs en un solo archivo.
5. Plan de Acción: Tu Lunes por la Mañana
¿Listo para integrar esto? Aquí tienes nuestra receta:
- Habilita el Acceso: Necesitas una suscripción Plus/Pro. No hay acceso gratuito actualmente.
- El Test del "Becario": Asigna a GPT-5.3 una tarea que le darías a un becario (ej: "Escribe los tests unitarios para este módulo y arregla lo que falle").
- Auditoría de Secretos: ADVERTENCIA. No subas tus archivos .env o credenciales. Aunque OpenAI promete privacidad, el riesgo de filtración en logs es real.
- Adopta el "Steering": No lances el prompt y te vayas a por café. Quédate mirando. La nueva capacidad de interrumpir y redirigir al agente es donde obtienes el valor real.
El desarrollo de software ha cambiado. Ya no escribimos código; gestionamos a los que escriben código. Y el nuevo gestor eres tú.
✅ Próximos pasos: Si quieres llevar esto al siguiente nivel, aprende sobre Vibe Coding y desarrollo con agentes autónomos.
GPT-5.3-Codex
OpenAI
Agentes IA
DevOps
NVIDIA GB200
Ciberseguridad
Ingeniería de Software