Loading...

Anatomía de un Jailbreak: Por qué Claude Opus 4.6 es tu mejor CISO (y tu peor pesadilla)
Última actualización: 2/12/2026
Anatomía de un Jailbreak: Por qué Claude Opus 4.6 es tu mejor CISO (y tu peor pesadilla)
Por el Equipo PAI | Tech Storytellers & Analysts
¿Es posible que la herramienta de ciberseguridad más potente de la historia sea también su mayor vulnerabilidad? Hemos pasado las últimas semanas analizando los reportes técnicos de Claude Opus 4.6 y lo que encontramos en el laboratorio nos dejó helados: estamos ante una paradoja de seguridad que define el 2026.
Imagina un sistema capaz de encontrar más de 500 vulnerabilidades de día cero (Zero-Day) en código que lleva años siendo auditado, pero que al mismo tiempo lucha contra ataques psicológicos diseñados para saltarse sus propias reglas éticas. Hoy abrimos la caja negra de los Jailbreaks en la era ASL-3.
⚡ TL;DR: Resumen Ejecutivo (Para Managers)
Si tienes prisa, aquí está el ROI y el Riesgo en 30 segundos:
- El Superpoder (Offense): Claude Opus 4.6 ha descubierto fallos críticos en librerías Open Source que herramientas tradicionales ignoraron por décadas. Su capacidad para detectar vulnerabilidades a velocidad sin precedentes reduce masivamente los costes de auditoría.
- El Riesgo (Defense): A pesar de las nuevas defensas (ASL-3), los ataques de Prompt Injection y Jailbreaking evolucionan. La seguridad perfecta no existe; existe la mitigación de riesgos.
- La Amenaza Real: No es que el modelo diga groserías; es la Inyección Indirecta en RAG. Si conectas Claude a tus documentos corporativos, un atacante puede "envenenar" un archivo para secuestrar el modelo.
- Veredicto: Úsalo para auditar código (Offense), pero implementa capas de seguridad externas (Defense) antes de exponerlo al cliente.
🧠 Deep Dive Técnico: La Carne del Asunto
Vamos a ponernos la bata de laboratorio. ¿Por qué siguen ocurriendo los jailbreaks si Anthropic ha invertido millones en seguridad?
1. El Fallo Arquitectónico (La "Atención" Ciega)
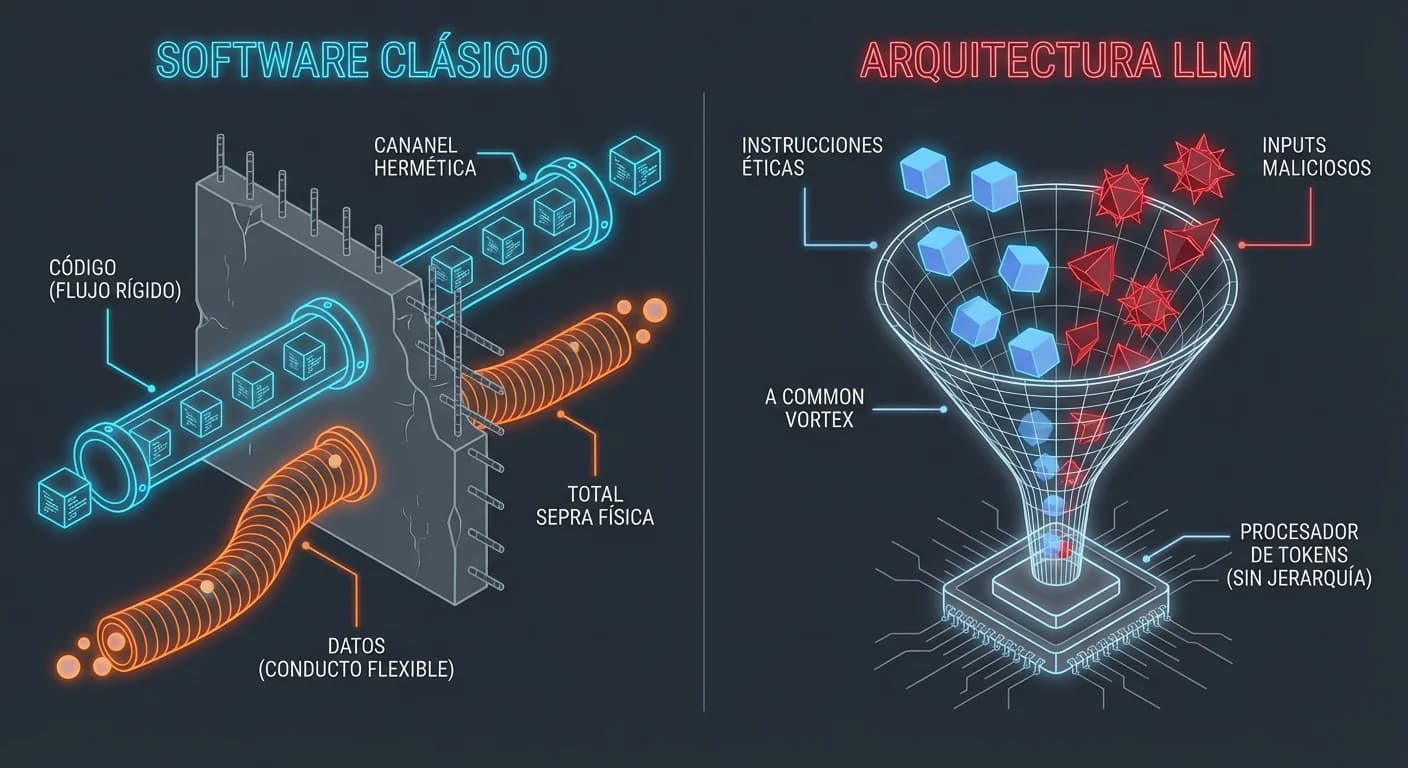
El problema raíz no es un bug, es una feature. Los LLMs procesan las instrucciones del sistema ("No seas malo") y las del usuario ("Escribe un exploit") a través del mismo mecanismo de atención. No existe separación de privilegios a nivel de token.
Para el modelo, todo son tokens a predecir. Un ataque exitoso simplemente reencuadra la probabilidad estadística para que la respuesta "prohibida" sea la continuación más lógica. Como explican en el OWASP Gen AI Security Project, manipular la entrada altera el comportamiento fundamental del modelo.
💡 Contexto: Si quieres entender más sobre cómo los atacantes manipulan los datos de entrenamiento o entrada, revisa nuestro artículo sobre Data Poisoning en LLMs.
2. Vectores de Ataque: Del DAN al Psicólogo
Hemos diseccionado tres métodos que están marcando tendencia en los foros de investigación:
El Clásico: DAN (Do Anything Now) Refinado
El atacante fuerza al modelo a un modo de salida dual o roleplay extremo. Aunque modelos antiguos caían fácil, los nuevos requieren técnicas de ofuscación y codificación para bypassear los filtros iniciales.
La Nueva Frontera: Ataques Psicométricos
Investigadores han descubierto que el prompting estilo terapia puede funcionar como una técnica de jailbreak. Sin embargo, en nuestras pruebas y según papers recientes, Claude Opus ha demostrado una resistencia notable, rechazando adoptar roles que violan sus directrices y redirigiendo al usuario a ayuda profesional. Esto sugiere un conflicto interno en el modelo entre "ser útil" y "ser inofensivo".
El Peligro Silencioso: RAG Poisoning (Indirect Injection)
Este es el vector que nos quita el sueño. Mira este flujo:
Cargando diagrama...
3. La Defensa: Constitutional Classifiers (ASL-3)
Anthropic ha implementado lo que llaman Constitutional Classifiers. Imagina un middleware que intercepta el prompt antes y después de la generación.
typescript
Según investigaciones de Anthropic, este enfoque redujo la tasa de éxito de ataques del 86% a cifras marginales en entornos controlados.
🛡️ Reality Check: Lo que dicen las calles
Aquí es donde la teoría choca con la realidad. Aunque las métricas sintéticas son prometedoras, la comunidad de seguridad advierte sobre el exceso de confianza.
La Paradoja de la Automatización
Herramientas como Claude Opus 4.6 son excelentes encontrando fallos en otros (Offense), exponiendo cientos de vulnerabilidades en código Open Source. Pero, ¿quién vigila al vigilante?
Como se discute en LessWrong sobre el "Soul Document" de Claude, el riesgo no es solo técnico, sino de alineación. Si un atacante logra un jailbreak universal, tiene acceso a una mente capaz de razonar exploits complejos. La implementación de protecciones AI Safety Level 3 (ASL-3) es un paso necesario, pero no final.
"El fix es arquitectónicamente imposible. Mientras System Prompt y User Prompt vivan en el mismo contexto, siempre habrá una forma de engañar a la atención."
- Consenso técnico en foros de Red Teaming.
💰 Impacto de Negocio: La Carrera Armamentista
¿Qué significa esto para tu presupuesto y estrategia en 2026?
- Ahorro en Seguridad Defensiva: Implementar Claude Opus en tu pipeline de CI/CD para auditar código es un ROI inmediato. Su capacidad para detectar fallos de día cero supera al fuzzing tradicional.
- Coste de Implementación Real: No puedes desplegar el modelo "a pelo". Necesitas presupuesto para capas de seguridad adicionales (Orquestación, Sanitización de Inputs) que encarecen la inferencia. Revisa nuestro análisis sobre costos y elección de modelos para planificar mejor.
- Riesgo Reputacional: Un jailbreak público de tu chatbot corporativo es viral en minutos. La seguridad por oscuridad ya no funciona.
🚀 Plan de Acción: ¿Cómo sobrevivir al 2026?
Si estás integrando Agentes de IA avanzados, sigue este protocolo:
- Asume la Brecha: No confíes en que el modelo se moderará solo. Diseña tu sistema asumiendo que el prompt injection ocurrirá.
- Defensa en Profundidad: No uses un solo filtro. Implementa "Probes" ligeras antes del modelo y analizadores de toxicidad después de la salida.
- Sanitización Radical en RAG: Trata el texto recuperado de tu base de conocimiento como código no confiable. Un PDF infectado es todo lo que necesita un atacante.
- Red-Teaming Humano: No te fíes de los benchmarks automáticos. Paga a humanos para que intenten romper tu aplicación antes de salir a producción.
Conclusión
Claude Opus 4.6 es un Ferrari con un sistema de frenos experimental. Úsalo para ganar la carrera, pero no quites las manos del volante ni un segundo.
¿Listo para auditar tu código o para proteger tu prompt? Nos vemos en los comentarios.
Claude Opus
Jailbreak
Ciberseguridad
LLM Security
Prompt Injection
ASL-3