Loading...
Gemini 3 Deep Think: Análisis Técnico de la Arquitectura que Rompió los Benchmarks
Última actualización: 2/14/2026
Gemini 3 Deep Think: La Arquitectura de Razonamiento que Rompió los Benchmarks
En el Equipo PAI no nos impresionamos fácilmente con las notas de prensa de Mountain View. Pero lo que Google liberó el 12 de febrero de 2026 no es solo una "actualización"; es una declaración de guerra arquitectónica. Gemini 3 Deep Think no solo ha superado a OpenAI en benchmarks críticos; ha cambiado la física de cómo consumimos inferencia.
Si ya leíste nuestro análisis completo de Gemini 3, sabes que el salto es cuantitativo. Hoy abrimos el capó de este motor de razonamiento para mostrarte lo que el marketing no dice: la arquitectura de backtracking real, el coste oculto en los tokens de salida y por qué la brecha técnica en razonamiento abstracto se ha vuelto peligrosa para la competencia.
Aquí está el desglose técnico.
⚡ TL;DR: Resumen Ejecutivo (Para el CTO con prisa)
- El Titular: Gemini 3 Deep Think alcanzó un 48.4% en "Humanity's Last Exam" (vs 26.6% de OpenAI o3). Es, hoy por hoy, el modelo más capaz para problemas científicos no resueltos.
- La Arquitectura: Integra sistemas agénticos como Aletheia. No es simple Chain of Thought; es exploración multi-ruta con verificación y revisión iterativa.
- El Costo Oculto: ⚠️ Cuidado. Los "pensamientos" del modelo se facturan como tokens de salida. Una respuesta final breve puede costarte miles de tokens de cómputo invisible (aprox. $1/hora en uso continuo).
- El ROI: Indiscutible para I+D (Física, Matemáticas, Código complejo). Ruinoso para chatbots o tareas CRUD.
🔬 Deep Dive Técnico: La Ingeniería del "Pensamiento Profundo"
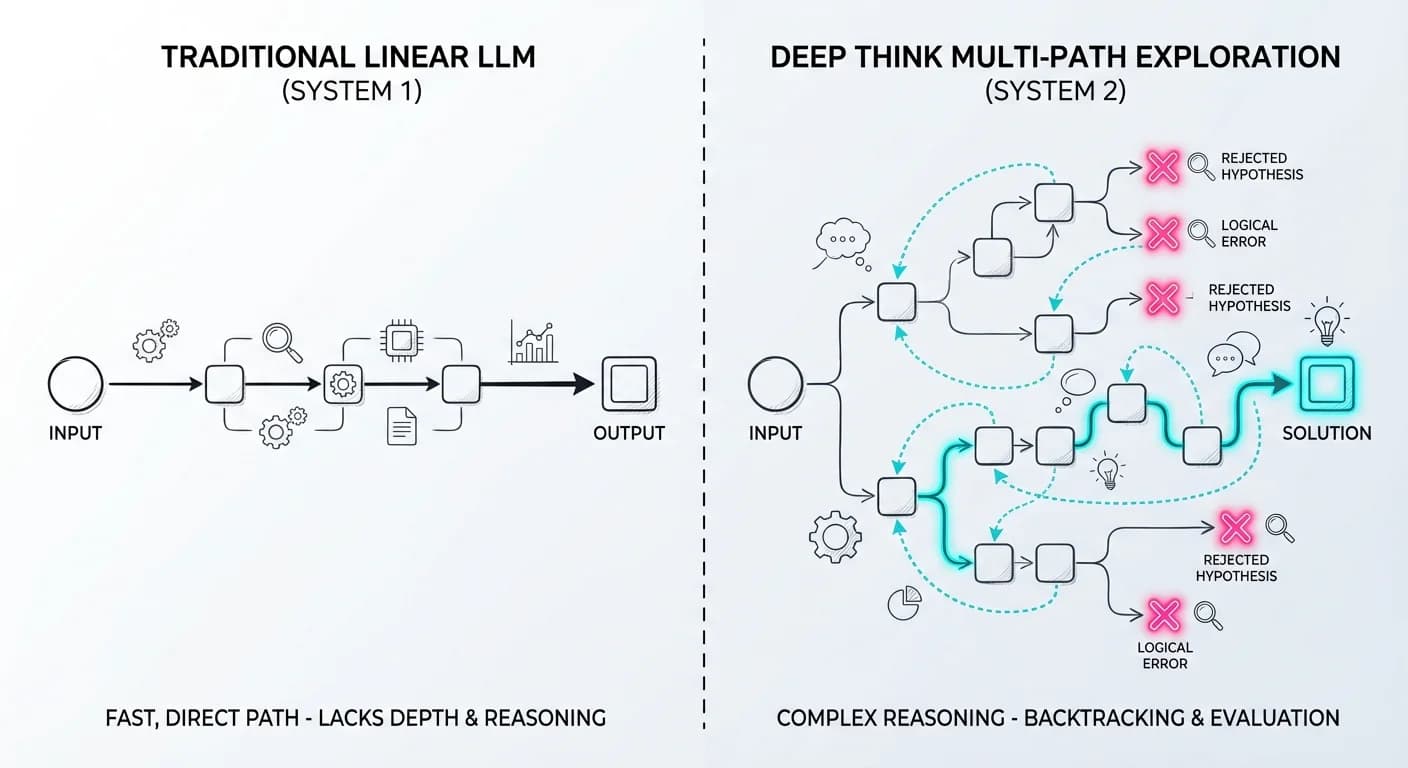
Olvídate de la magia. Aquí hay ingeniería de sistemas puros. A diferencia de los LLMs tradicionales que predicen el siguiente token en una cascada lineal, Deep Think opera bajo un Paradigma de Computación en Tiempo de Inferencia.
1. El Algoritmo: Branching & Pruning (Sistema 2)
Lo que Google comercializa como "Deep Think" es una implementación masiva de Tree of Thoughts (ToT) potenciada por agentes especializados. Según los papers técnicos de DeepMind, esto se materializa en agentes como Aletheia, diseñados específicamente para la investigación matemática autónoma.
Cuando le das un problema complejo (ej. un teorema matemático o un bug de carrera en C++), el sistema no corre hacia la respuesta. Ejecuta un ciclo de generación, verificación y revisión:
Cargando diagrama...
El componente clave es la capacidad de "admitir el fracaso". Si todas las ramas llevan a callejones sin salida, el modelo prefiere decir "No puedo resolver esto" a alucinar una respuesta, una característica crítica para la investigación científica.
2. Controlando la "Intensidad del Pensamiento"
Google expone esto vía API. No es un simple slider de temperatura; controla el presupuesto de computación y la profundidad del árbol de búsqueda. Al usar niveles altos de razonamiento, no estás pagando por una respuesta mejor redactada. Estás pagando por docenas de borradores internos que el modelo escribe, evalúa y destruye antes de mostrarte el resultado final.
📉 Reality Check: Los Datos Duros y los Trade-offs
Aquí es donde separamos el hype de la realidad de producción. Hemos analizado los benchmarks y los reportes de la comunidad técnica.
El Benchmark que Importa: Humanity's Last Exam (HLE)
El HLE está diseñado para ser imposible de memorizar, compuesto por problemas de nivel doctorado.
| Modelo | Puntuación HLE | Notas |
|---|---|---|
| Gemini 3 Deep Think | 48.4% | Sin herramientas externas |
| OpenAI o3 | 26.6% | Referencia estándar |
| DeepSeek R1 | 9.4% | Alternativa Open Weight |
La Lectura: Gemini casi duplica la capacidad de razonamiento puro de sus competidores más cercanos. La brecha en razonamiento abstracto es ahora un abismo.
El Monstruo del Código: Elo 3455 en Codeforces
Para los managers de ingeniería: Un Elo de 3455 en Codeforces coloca a esta IA en el Top 8 mundial de programadores competitivos.
Esto no significa que escriba mejor CSS que tú. Significa que puede resolver problemas algorítmicos de optimización extrema que el 99.9% de los ingenieros humanos no pueden plantear. Si tienes problemas de scheduling complejos o optimización de rutas, este es tu modelo.
⚠️ La Verdad Incómoda: Latencia y Costos
Google no publica cifras oficiales de latencia. ¿Por qué? Porque son altas. En modo deep, una consulta puede tardar desde 10 segundos hasta varios minutos.
La Trampa del Pricing: Los tokens de "pensamiento" (el proceso interno) se facturan como tokens de salida.
- Si el modelo "piensa" durante 5,000 tokens para darte una respuesta de 100 tokens, pagas por 5,100 tokens de salida cara.
- Cálculo de Servilleta: Análisis independientes sugieren que a 100 tokens/seg, el costo operativo ronda $1 por hora de uso continuo. No parece mucho, hasta que lo escalas a 1,000 usuarios concurrentes.
💼 Impacto de Negocio: ¿Dónde está el ROI?
No uses Deep Think para resumir emails. Es como usar un cohete Falcon 9 para ir a comprar pan. Úsalo aquí:
- I+D de Materiales y Farmacia: El Wang Lab en la Universidad de Duke ya lo ha utilizado para optimizar el crecimiento de cristales para semiconductores. El modelo navega espacios de parámetros multidimensionales mejor que la intuición humana.
- Conversión Multimodal Compleja: De boceto a objeto 3D. La capacidad de inferir geometría 3D desde un dibujo 2D requiere un razonamiento espacial que los modelos anteriores no tenían, permitiendo generar modelos imprimibles desde esquemas.
- Auditoría de Código Crítico: Úsalo para auditar contratos inteligentes o algoritmos de seguridad donde el costo del fallo es infinitamente superior al costo del token.
🚀 Plan de Acción: Tu Estrategia para el Q2 2026
¿Cómo implementar esto sin quebrar el banco? Sigue esta estrategia:
- Para Desarrolladores (The Router Pattern): Si tienes acceso a la API, implementa un Top-K Routing. Envía el 90% del tráfico a modelos Flash o Pro. Envía solo el 10% de problemas de "lógica dura" a Deep Think.
- Para Managers: No compres suscripciones "Ultra" para todo el equipo indiscriminadamente. Identifica a tus 2-3 "Solver Architects" que enfrentan problemas de hoja en blanco y dales acceso. El resto no notará la diferencia.
- El Experimento: Toma ese problema de optimización en tu backlog que lleva meses marcado como "investigar" y pásalo por Deep Think. Los resultados te sorprenderán.
💡 The Lightbulb Moment: No necesitas una IA más rápida. Necesitas una IA que sepa detenerse, pensar y corregirse a sí misma antes de responder. Gemini 3 Deep Think es lenta, cara y piensa demasiado... pero cuando acierta, es sobrehumana.
Si quieres profundizar en cómo integrar estos modelos en flujos de trabajo autónomos, revisa nuestra guía sobre Agentes de IA y automatización.
Gemini 3
Deep Think
Tree of Thoughts
Benchmarks IA
Ingeniería de Prompts
Costos LLM