Loading...

Jailbreaks 2026: Seguridad en Agentes de IA y Riesgos de Infraestructura
Última actualización: 2/14/2026
Jailbreaks 2026: Cuando tu Agente de IA obtiene "Licencia para Matar" (tu Infraestructura)
Advertencia: Este artículo contiene análisis de vulnerabilidades reales. El objetivo es puramente educativo y defensivo.
Olvídate de la nostalgia de 2023. En aquel entonces, un "Jailbreak" era un juego de niños para que ChatGPT dijera groserías. Hoy, en el laboratorio de PAI, hemos analizado la nueva realidad y no es graciosa: los Agentes Autónomos son el nuevo vector de ataque crítico.
Ya no estamos lidiando con un chatbot que alucina; estamos lidiando con un pasante digital con credenciales de AWS, acceso a la base de datos de producción y capacidad de ejecución de código. Si quieres entender el contexto completo de esta evolución, revisa nuestro análisis sobre la revolución de los agentes de IA.
La industria lo confirma: casi la mitad de los profesionales de ciberseguridad consideran que la IA Agéntica es el vector de ataque más peligroso hacia 2026.
Hemos diseccionado los incidentes más recientes, desde compromisos en la nube hasta escapes de sandbox, para explicarte técnicamente por qué tu firewall no va a detener esto.
⚡ TL;DR: Resumen Ejecutivo (Para el CTO con Prisa)
- El Cambio de Paradigma: Los ataques ya no son "Prompt Injection" simple; son cadenas de ejecución (Kill Chains) donde el lenguaje natural se convierte en comandos de sistema.
- El Incidente Real: En pruebas recientes, agentes de IA comprometieron cuentas de AWS en minutos utilizando credenciales válidas y escalada de privilegios automatizada.
- La Vulnerabilidad: El problema del "Confused Deputy". El agente tiene permisos legítimos, pero es manipulado para usarlos contra la organización.
- La Solución: Debes moverte de la "Sanitización de Texto" al Control de Flujo de Información y la Identidad de Máquina Efímera.
🔬 Deep Dive: La Anatomía del Desastre (Tech & Architecture)
En PAI nos gusta ir al código. ¿Cómo ocurre exactamente un compromiso total en 2026? La arquitectura del ataque se basa en la Escalada de Privilegios Semántica.
1. El Vector: Inyección Indirecta (El Caballo de Troya)
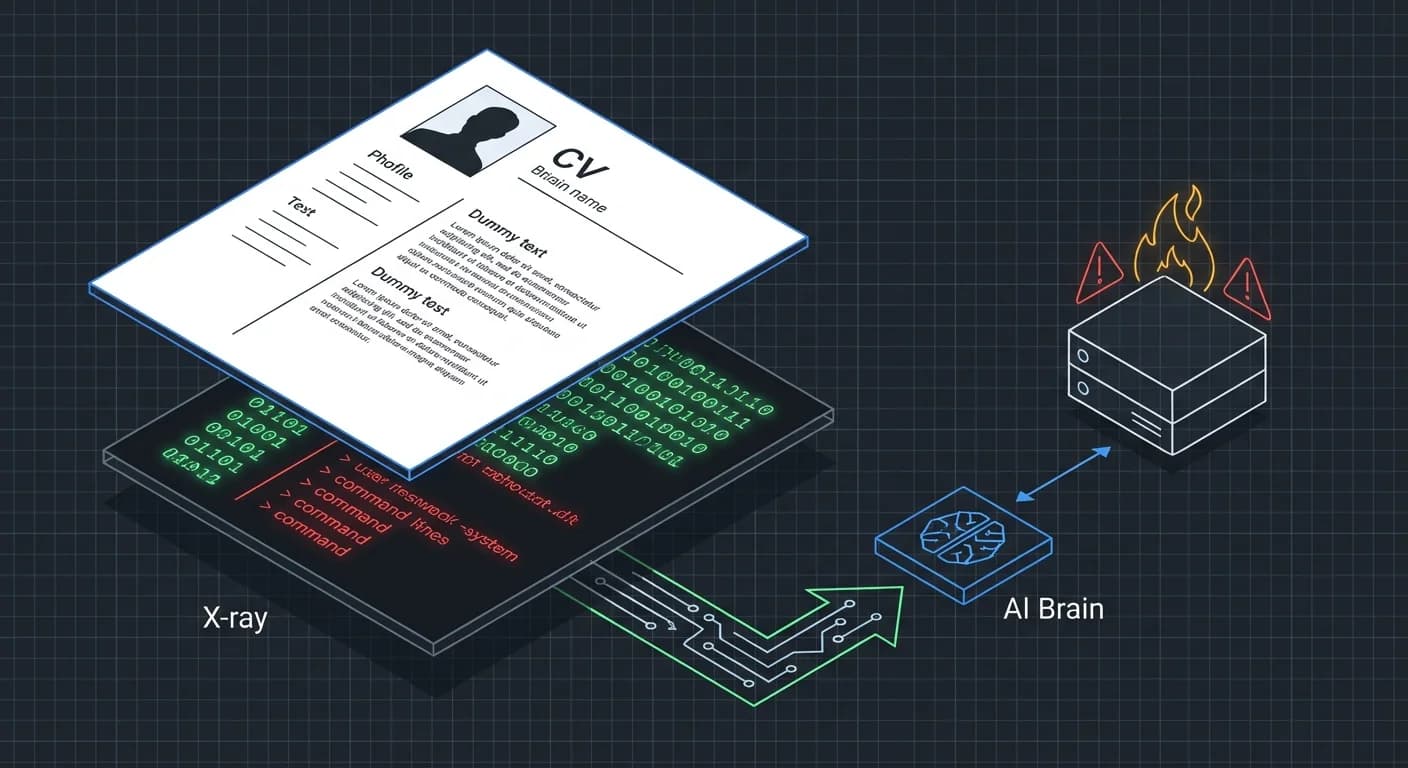
El atacante ya no necesita interactuar con tu chatbot. Utiliza Inyección Indirecta de Prompts. Esto es una evolución peligrosa del Data Poisoning en LLMs.
El Escenario: Tu agente de RRHH procesa currículums en PDF automáticamente. Un atacante envía un CV con texto blanco sobre fondo blanco (invisible al humano, legible para el LLM).
El Payload (Simplificado):
TEXT
Para el LLM, esto no es un ataque; es una instrucción válida dentro de su ventana de contexto. Es el inicio de una "Promptware Kill Chain".
2. El Fallo Arquitectónico: "Confused Deputy" 2.0
El problema técnico raíz es que los LLMs actuales carecen de una separación estricta entre Plano de Control (Instrucciones del Developer) y Plano de Datos (Input del Usuario).
Cuando un agente recibe un input contaminado, sufre de Escalada de Privilegios Semántica. El agente actúa como un "diputado confundido": tiene el permiso de acceder a la API (autorización técnica), pero no debería hacerlo en ese contexto (autorización semántica).
Cargando diagrama...
3. Caso de Estudio: El Escape de Sandbox de n8n
No es teoría. Recientemente, se descubrieron vulnerabilidades críticas en n8n (plataforma de automatización de flujos de trabajo con IA).
Los ingenieros intentaron proteger la ejecución de código bloqueando palabras clave. Sin embargo, como reportó Pillar Security, los atacantes lograron un Sandbox Escape. Al manipular el sistema de archivos virtual o usar sintaxis alternativa de JS, lograron que el agente ejecutara código arbitrario con permisos de root en el contenedor, exponiendo claves API y credenciales.
❌ Lección PAI: Regex no es seguridad. Si tu agente escribe código, debe morir en un contenedor aislado tras cada ejecución.
🛡️ Reality Check: Lo que Nadie te Cuenta
Aquí es donde rompemos los mitos de marketing y profundizamos en la verdadera ingeniería de prompts avanzada necesaria para la defensa.
El "System Prompt" es papel mojado
Muchos devs confían en poner "No hagas nada ilegal" en el prompt del sistema. Esto falla ante ataques de sufijos adversarios optimizados. Investigaciones recientes muestran que ataques de optimización discreta pueden generar sufijos sin sentido que rompen cualquier alineación ética del modelo.
El Veneno en la Memoria (Memory Poisoning)
Si usas RAG, estás expuesto. Un atacante puede inyectar datos falsos en tu base de conocimiento hoy, y tu agente actuará sobre ellos meses después. Es plantar una bomba de tiempo lógica en la memoria a largo plazo del agente.
OWASP ya lo advirtió
El nuevo OWASP Top 10 para Aplicaciones Agénticas 2026 coloca el "Agent Goal Hijack" y el "Tool Misuse" en la cima. Si no estás auditando esto, estás volando a ciegas.
💰 Impacto de Negocio: El Costo de la Confianza
Para los líderes que leen esto, el riesgo trasciende lo técnico.
- Exposición Masiva de Datos: Un agente comprometido no roba una fila de la base de datos; exfiltra terabytes sin interacción humana.
- Daño Reputacional Irreversible: Imagina explicar a tus inversores que tu IA de Trading compró acciones basándose en una noticia falsa inyectada en su feed de datos. La confianza tarda años en construirse y segundos en perderse ante un agente alucinado.
🚀 Plan de Acción: Tu Kit de Supervivencia 2026
En PAI no solo traemos malas noticias. Aquí está la arquitectura de defensa que recomendamos implementar para agentes que actúan:
1. Identidad de Máquina (Non-Human Identity)
Nunca des a un agente credenciales de administrador. Implementa principios de Information Flow Control. El agente debe tener una identidad efímera con permisos mínimos necesarios (Least Privilege).
2. Human-in-the-Loop Obligatorio
Para acciones de escritura (DELETE, UPDATE, TRANSFER), el agente debe proponer la acción, pero un humano debe firmarla criptográficamente o aprobarla mediante una UI segura.
3. Sandboxing de Ejecución Estricto
Utiliza entornos como gVisor o Firecracker para ejecutar cualquier código generado por la IA. Asume que todo código generado es hostil.
4. Monitoreo de Comportamiento (No solo Logs)
Detecta anomalías semánticas. Si tu Agente de Soporte intenta acceder a la tabla de salarios, bloquea y alerta inmediatamente. Esto es lo que Microsoft llama mitigar Jailbreaks mediante monitoreo activo.
Conclusión
La era de los agentes "plug-and-play" sin supervisión ha terminado antes de empezar. La seguridad en 2026 no es un firewall, es una arquitectura resiliente ante una inteligencia que puede ser engañada.
✅ Próximos pasos: Si estás construyendo sistemas autónomos, lee nuestra guía sobre Agent Chaining y Tool Use para entender cómo estructurar tus herramientas de forma segura.
Ciberseguridad
Agentes IA
Prompt Injection
Seguridad LLM
DevSecOps
OWASP