Loading...

NVIDIA PersonaPlex-7B: Deconstruyendo el Santo Grial del Audio Full-Duplex
Última actualización: 2/18/2026
NVIDIA PersonaPlex-7B: Deconstruyendo el Santo Grial del Audio Full-Duplex
¿Alguna vez has intentado interrumpir a un asistente de voz mientras hablaba, solo para que siga con su monólogo como si no existieras? Ese es el dolor del Turn-Taking artificial. Durante años, hemos vivido bajo la tiranía del pipeline en cascada: Escuchar → Transcribir (ASR) → Pensar (LLM) → Sintetizar (TTS). Es lento, rígido y, francamente, aburrido.
Hoy en el laboratorio de PAI hemos destripado NVIDIA PersonaPlex-7B-v1. Sobre el papel, promete ser el fin de la latencia: un modelo full-duplex que escucha y habla simultáneamente. Pero tras mirar bajo el capó y analizar los benchmarks, la historia tiene matices. Es una maravilla de ingeniería basada en la arquitectura Moshi, sí, pero viene con una factura de hardware que hará sudar a tu CFO.
Analizamos la arquitectura, el código y la realidad de producción de esta bestia de 7 billones de parámetros.
TL;DR: Resumen Ejecutivo
- La Tecnología: Un modelo Audio-a-Audio puro. No hay texto intermedio en el proceso de generación, lo que reduce drásticamente la latencia.
- El Benchmark: Logra una latencia de respuesta de 0.17s y una tasa de toma de turno (Turn-Taking) del 90.8%.
- El Costo Oculto: Exige hardware de grado servidor. Se recomiendan al menos 24GB de VRAM para correrlo fluido. Olvida las laptops de consumo.
- Limitaciones V1: Actualmente es solo en inglés y presenta alucinaciones en conversaciones largas.
- Veredicto PAI: Ideal para R&D y entornos de alta privacidad on-premise. Aún inmaduro para reemplazar APIs comerciales en SaaS masivos.
1. Deep Dive Técnico: La Arquitectura "Dual-Stream"
Adiós al Pipeline ASR → LLM → TTS

Tradicionalmente, la IA conversacional funciona como un juego de teléfono descompuesto. Cada etapa añade latencia (lag) y pérdida de información (entonación, emoción). PersonaPlex tira esto a la basura. Basado en la arquitectura Moshi de Kyutai, NVIDIA ha creado un modelo que procesa tokens de audio discretos en un flujo continuo.
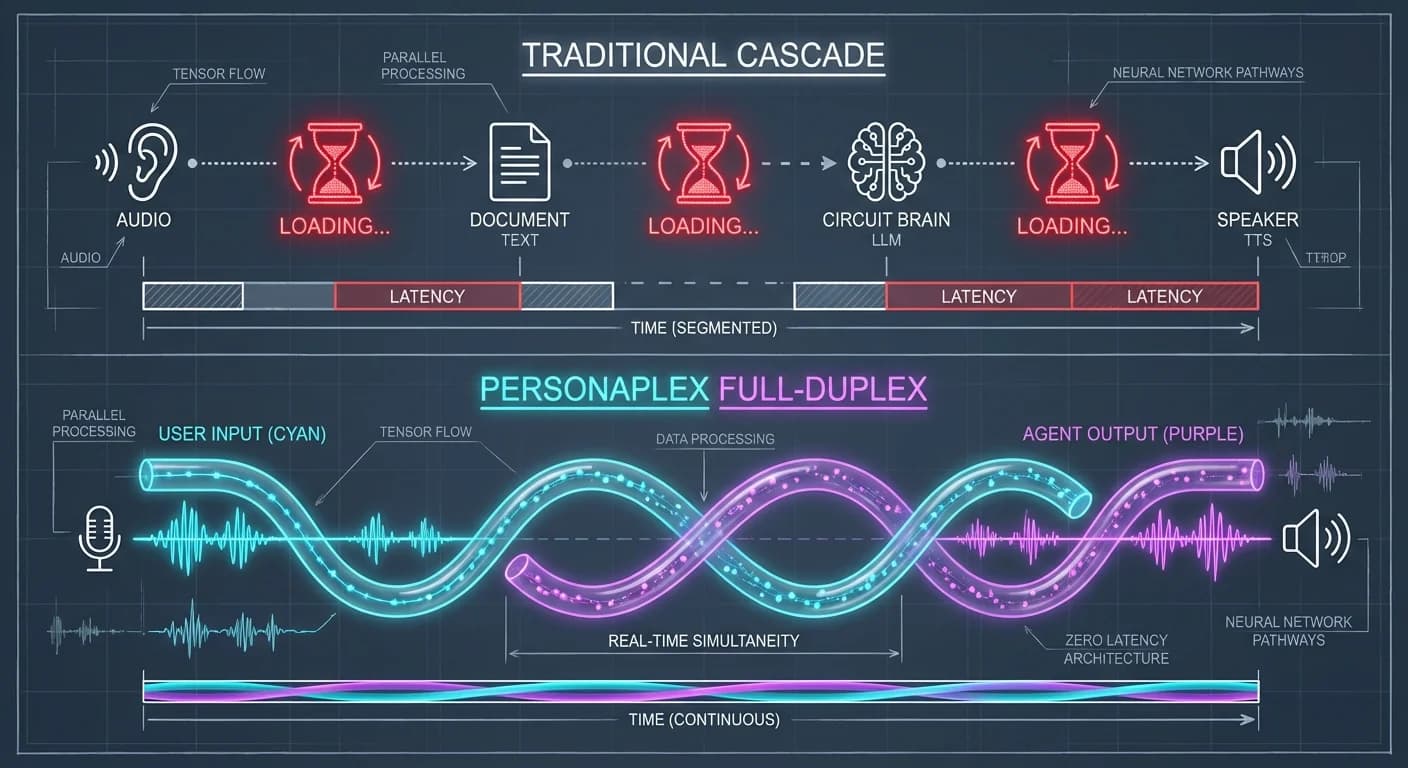
El modelo no "espera" a que termines. Mantiene dos canales abiertos en un estado compartido. Un canal codifica lo que dices en tiempo real (User Stream) y el otro genera la respuesta (Agent Stream) simultáneamente.
Diagrama de Flujo de Tensores
Cargando diagrama...
El Cerebro: Helium y Prompting Híbrido
El motor semántico debajo es Helium, un LLM de 7B parámetros que actúa como el cerebro lógico. Sin embargo, lo interesante para nosotros como ingenieros es el sistema de Prompting Híbrido tridimensional que NVIDIA implementó para controlar la anarquía del audio generativo:
- Voice Prompt (Audio): Un clip de referencia de pocos segundos. El modelo clona el timbre y estilo mapeándolo en su espacio latente. No es un fine-tuning, es in-context learning acústico.
- Text Prompt (Rol): Define la personalidad ("Eres un agente de soporte técnico impaciente").
- System Prompt (Reglas): Restricciones duras de negocio (hasta 200 tokens).
💡 The Lightbulb Moment: No estás enviando texto al modelo. Estás enviando vectores que representan sonido comprimido. Esto significa que el modelo puede "entender" un suspiro, una duda o un tono sarcástico, algo que se pierde totalmente en una transcripción de texto tradicional.
2. Reality Check: Lo que Duele en Producción
Aquí es donde el marketing choca con la pared de la realidad. Hemos analizado los reportes técnicos y nuestra propia experiencia desplegando modelos similares:
1. El Devorador de VRAM
NVIDIA sugiere GPUs como la A10G, A40 o RTX 4090. Esto no es opcional. El modelo necesita cargar los pesos de Helium (7B) más los codificadores/decodificadores de audio en memoria rápida.
- El problema: Un usuario reportó que intentar correrlo con menos de 24GB obliga a usar offloading a CPU, lo que destruye la latencia mágica de 170ms. El requisito de memoria es estricto para mantener el throughput necesario para el audio en tiempo real.
- Consecuencia: Si planeas escalar esto, tu factura de AWS/Azure en instancias
g5.2xlargeo superiores se disparará.
2. "Stuttering" y Amnesia Contextual
Aunque los benchmarks muestran un rendimiento superior en interrupciones, en el mundo real el modelo puede tartamudear. Esto ocurre cuando la generación de tokens de audio se desincroniza ligeramente del decoder. Además, al ser un modelo de 7B (pequeño para los estándares actuales de LLM), su ventana de contexto es limitada. No esperes que recuerde detalles complejos después de 10 minutos de conversación fluida.
3. La Barrera del Idioma
Actualmente, la versión v1 es exclusivamente en inglés. Aunque la arquitectura soporta teóricamente multilingüismo, el checkpoint liberado no. Si tu mercado es LatAm o España, esto es un bloqueante absoluto por ahora.
3. Implementación: Snippet de Configuración
Para los que quieran probarlo (y tengan la GPU para ello), el flujo no es un simple pip install. Requiere aceptar la licencia en Hugging Face y configurar el entorno con torch y flash-attention.
python
Nota: Asegúrate de tener los drivers de CUDA 12.x actualizados o el flash-attention fallará silenciosamente.
4. Impacto de Negocio: ¿Buy vs Build?
¿Por qué invertir en esto? La única razón real para adoptar PersonaPlex hoy sobre soluciones como OpenAI Realtime API es la Soberanía de Datos. Si estás en Banca, Salud o Gobierno, enviar audio crudo a la nube es un riesgo de compliance. PersonaPlex te permite tener una experiencia tipo "Her" corriendo totalmente en tu infraestructura privada.
Costos de Operación:
- Nube (API): Pagas por minuto. Escalado infinito.
- PersonaPlex (Self-Hosted): Pagas por GPU reservada ($0.76 - $1.00 USD/hora por A40). Necesitas mantener la infraestructura. La densidad de usuarios por GPU es baja (estimamos 4-6 sesiones concurrentes por tarjeta para mantener latencia).
5. Veredicto Final
PersonaPlex-7B es el "iPhone 1" de la IA de voz full-duplex: revolucionario, pero le falta la App Store y la batería dura poco. Es una pieza increíble de ingeniería que demuestra que el futuro es Audio-Nativo, pero hoy es una herramienta para Early Adopters.
Recomendación del Equipo PAI:
- Startups: Esperen. Usen APIs gestionadas.
- Enterprise R&D: Desplieguen un POC ya. La capacidad de clonar voces y manejar interrupciones on-prem es una ventaja competitiva que deben empezar a dominar hoy para el futuro de mañana.
NVIDIA
PersonaPlex
Audio LLM
Full-Duplex
Latencia
Ingeniería de Software
Generative AI