Loading...

Kimi Linear: ¿El fin de la atención cuadrática en Transformers?
Última actualización: 11/3/2025
Kimi Linear: ¿El fin de la atención cuadrática en Transformers?
Desde que los Transformers irrumpieron en el mundo de la IA, han tenido un "talón de Aquiles" bien conocido: su apetito voraz por la computación. A medida que procesan textos más largos, el costo computacional y la memoria necesaria crecen de forma cuadrática. Dicho de forma sencilla: si duplicas la longitud del texto, el esfuerzo para procesarlo se cuadruplica. Este es el muro contra el que chocan los modelos de lenguaje cuando intentan analizar libros enteros, bases de código masivas o transcripciones de horas de audio.
Durante años, la comunidad de IA ha buscado una solución en la "atención lineal". La promesa era simple: una arquitectura que escalara de forma lineal (doble de texto, doble de costo), mucho más eficiente. Sin embargo, esta eficiencia siempre venía con un sacrificio doloroso: una pérdida de rendimiento. Los modelos de atención lineal eran más rápidos y ligeros, pero no tan "inteligentes" como sus contrapartes de atención completa.
Hasta ahora.
Un nuevo paper del equipo de Kimi AI, titulado "Kimi Linear: An Expressive, Efficient Attention Architecture", presenta una arquitectura que no solo iguala, sino que supera el rendimiento de la atención completa en una amplia gama de tareas, manteniendo al mismo tiempo una eficiencia radicalmente superior. Esto no es solo una mejora incremental; es un posible punto de inflexión para el futuro de los modelos de lenguaje.
¿Qué es Kimi Linear y cuál es su "ingrediente secreto"?
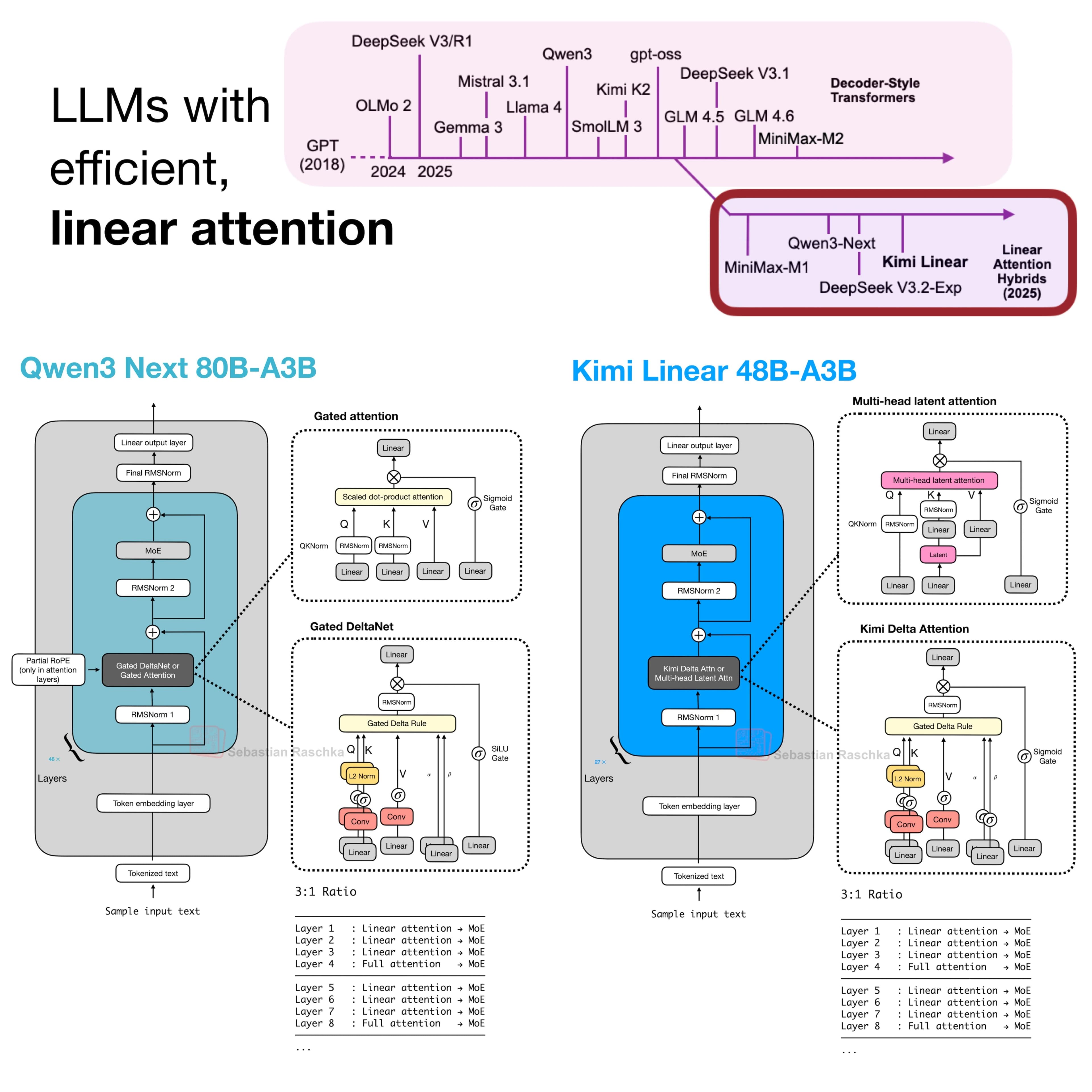
Kimi Linear no es una arquitectura puramente lineal. Es un modelo híbrido que combina lo mejor de dos mundos: la eficiencia de la atención lineal y la potencia de la atención completa.
El corazón de esta innovación es un nuevo módulo llamado Kimi Delta Attention (KDA), que extiende y refina conceptos de arquitecturas anteriores como Gated DeltaNet.
Imagina que la memoria de un modelo de lenguaje funciona como una orquesta. En los modelos de atención lineal anteriores, el director de orquesta solo tenía un control de volumen maestro para todos los instrumentos. Si necesitaba bajar el volumen de los violines, tenía que bajar el de toda la orquesta, perdiendo información valiosa de los demás instrumentos.
KDA le da al director un control de volumen individual para cada instrumento. Técnicamente, esto se llama "gating de grano fino a nivel de canal" (channel-wise fine-grained gating). Permite al modelo decidir con una precisión sin precedentes qué información es crucial mantener en su memoria y cuál puede "olvidar" en cada paso. Este control preciso sobre la memoria es lo que le permite ser tan expresivo y potente como la atención completa.
La "Receta Mágica": La arquitectura híbrida 3:1
Kimi Linear no reemplaza por completo la atención tradicional. En su lugar, utiliza una "receta" muy específica: intercala 3 capas de Kimi Delta Attention (KDA) con 1 capa de atención completa tradicional (MLA).
- Las capas KDA actúan como los "trabajadores eficientes". Se encargan de procesar la información a nivel local y mantener el contexto de forma súper eficiente, como si leyeran los párrafos de un libro.
- La capa MLA actúa como el "supervisor estratégico". Periódicamente, revisa el trabajo de las capas KDA y consolida una visión global de todo el texto, asegurándose de que no se pierda el hilo conductor de la historia.
Este ratio 3:1 resultó ser el "punto dulce" que ofrece el mejor equilibrio entre rendimiento y eficiencia, evitando que el modelo se "pierda" en contextos extremadamente largos, un problema común en arquitecturas puramente lineales.
Es interesante notar que otros modelos recientes, como Qwen3-Next, también han adoptado una estrategia híbrida 3:1. La diferencia clave, sin embargo, radica en el refinamiento de Kimi Linear: su uso de compuertas de grano fino a nivel de canal, en lugar de a nivel de cabeza, le otorga un control de memoria superior, lo cual es crucial para tareas de razonamiento en contextos largos.
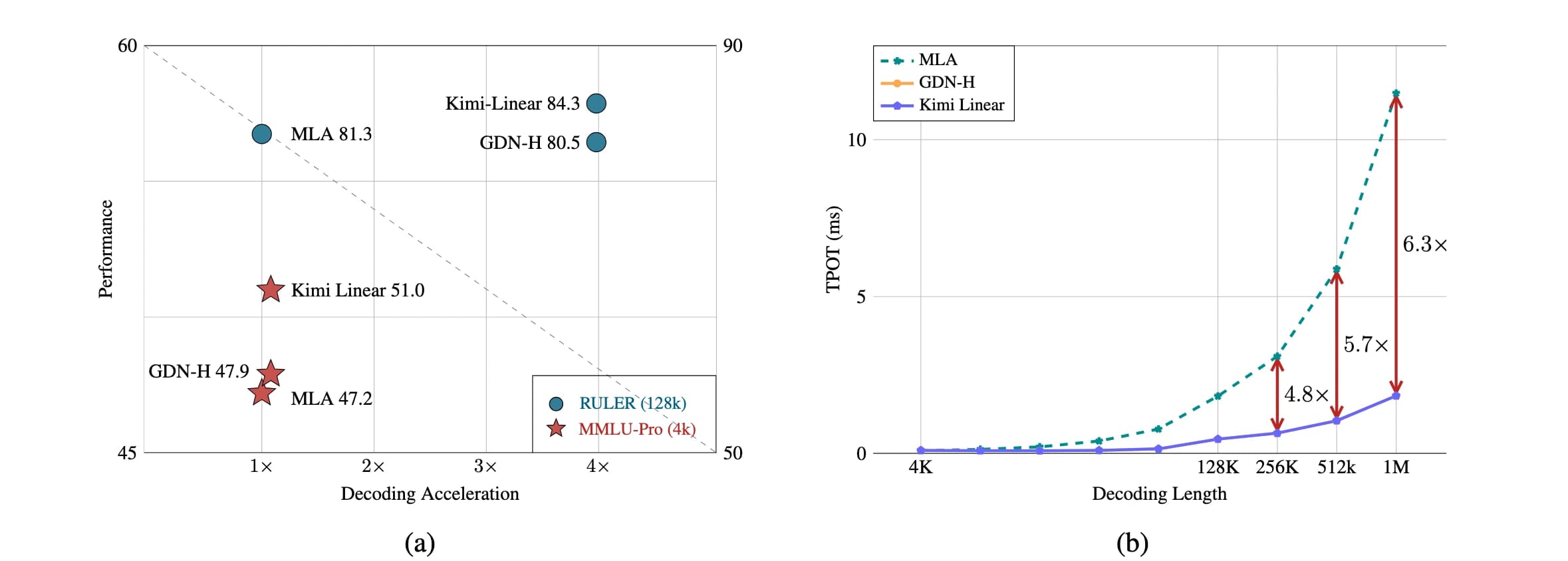
Resultados que hablan por sí solos: Más rápido y mejor
Aquí es donde Kimi Linear brilla. El paper presenta una comparación exhaustiva contra modelos de atención completa con la misma cantidad de parámetros y datos de entrenamiento. Los resultados son contundentes:
- Rendimiento Superior en TODO: Kimi Linear no solo es mejor en tareas de contexto largo. Supera a la atención completa en casi todos los escenarios evaluados: pre-entrenamiento general, ajuste fino para seguir instrucciones (SFT) y aprendizaje por refuerzo (RL) para tareas de razonamiento complejo.
- Eficiencia Radical:
- 75% menos uso de KV Cache: La "memoria a corto plazo" del modelo se reduce drásticamente, lo que permite procesar contextos mucho más largos con el mismo hardware.
- Hasta 6 veces más rápido: En tareas de generación de texto con un contexto de 1 millón de tokens, Kimi Linear es hasta 6 veces más rápido que un modelo de atención completa.
NoPE: Una decisión contraintuitiva que funciona
Uno de los detalles más fascinantes es que las capas de atención completa en Kimi Linear no usan codificación de posición explícita (NoPE), como el popular RoPE. En su lugar, delegan toda la responsabilidad de entender el orden y la posición de las palabras a las capas KDA.
Esto, que parece contraintuitivo, tiene dos ventajas clave:
- Simplifica el entrenamiento para contextos largos, ya que no es necesario "estirar" o ajustar las codificaciones de posición.
- Permite utilizar Multi-Query Attention (MQA), una versión aún más optimizada de la atención, durante la inferencia, lo que contribuye a su increíble velocidad.
¿Por qué Kimi Linear es un cambio de juego?
- El fin de un compromiso: Ya no es necesario elegir entre la eficiencia de la atención lineal y el rendimiento de la atención completa. Kimi Linear ofrece lo mejor de ambos mundos.
- IA para contextos masivos: Abre la puerta a aplicaciones que antes eran computacionalmente prohibitivas: análisis de libros enteros, bases de código de proyectos completos, o la creación de agentes de IA que puedan mantener conversaciones coherentes durante horas.
- Democratización de la IA: Al ser mucho más eficiente, Kimi Linear permite que modelos de lenguaje muy potentes se ejecuten en hardware menos costoso, haciendo la tecnología más accesible para investigadores y empresas.
- Un reemplazo "Plug-and-Play": El equipo de Kimi ha liberado el código y los modelos, y están diseñados para ser un "drop-in replacement", lo que facilita su adopción por parte de la comunidad.
Kimi Linear no es solo un nuevo paper académico. Es una solución de ingeniería robusta y probada a gran escala que podría redefinir la arquitectura estándar de los modelos de lenguaje en los próximos años, abriendo una nueva era de eficiencia y capacidad.
Recursos para profundizar
Para aquellos interesados en explorar más a fondo, el equipo de Moonshot AI ha liberado una gran cantidad de recursos:
- El Paper Original: Lee la investigación completa en arXiv.
- Código y Kernels: Explora la implementación en GitHub, incluyendo los kernels de KDA y la integración con vLLM.
- Modelos Pre-entrenados: Descarga y prueba los modelos directamente desde Hugging Face.
- Análisis de Expertos: Sigue la discusión de expertos como Sebastian Raschka en X (Twitter) para un análisis más profundo.
kimi linear
atencion lineal
transformers
arquitectura llm