Loading...

GPT-5.2-Codex: Análisis Técnico y la Mentira del Context Window
Última actualización: 1/19/2025
GPT-5.2-Codex: La Autopsia Técnica (y por qué tu "Context Window" te está mintiendo)
"El código es fácil. El contexto es lo difícil."
1. El Gancho: La Promesa del "Ingeniero Fantasma"
Todos hemos escuchado el pitch de ventas: un modelo que no solo completa código, sino que actúa como un ingeniero. Un sistema que arregla bugs mientras duermes. Pero en nuestro laboratorio, somos escépticos por diseño.
La llegada de GPT-5.2-Codex promete flujos de trabajo "agentic" y una ventana de contexto masiva, pero ¿qué pasa cuando la factura de la API llega y el código sigue fallando en los edge cases?
La realidad es que estamos ante un salto arquitectónico brutal, pero no es la "magia" que vende el marketing. Es ingeniería pura, con trade-offs de latencia y costos que, si no calculas bien, pueden comerse tu presupuesto de cloud antes del mediodía.
2. TL;DR: Resumen Ejecutivo (Para el CTO con prisa)
Si solo tienes 30 segundos entre reuniones, esto es lo que necesitas saber antes de aprobar la tarjeta de crédito:
- El Ahorro Real: Introduce "Response Compaction" nativa, una técnica que permite gestionar contextos extendidos sin la explosión lineal de costos habitual. Esto no es solo ahorro; es viabilidad económica para sesiones largas.
- El Rendimiento: Alcanza un impresionante 75.40% en SWE-bench Verified. Supera a todo lo anterior, pero implica que fallará o requerirá supervisión humana el 25% del tiempo. No despidas a tus QA.
- El Costo Oculto: La ventana de 400k tokens es engañosa. 128k están reservados para salida, dejándote con ~270k reales de entrada efectiva para tu base de código.
- Veredicto: Ideal para refactorización de legacy y migraciones (Java a Kotlin, etc.). Demasiado lento y caro para usarlo como un simple "autocompletar" en el IDE.
3. Deep Dive Técnico: Anatomía de la "Compresión con Pérdida"
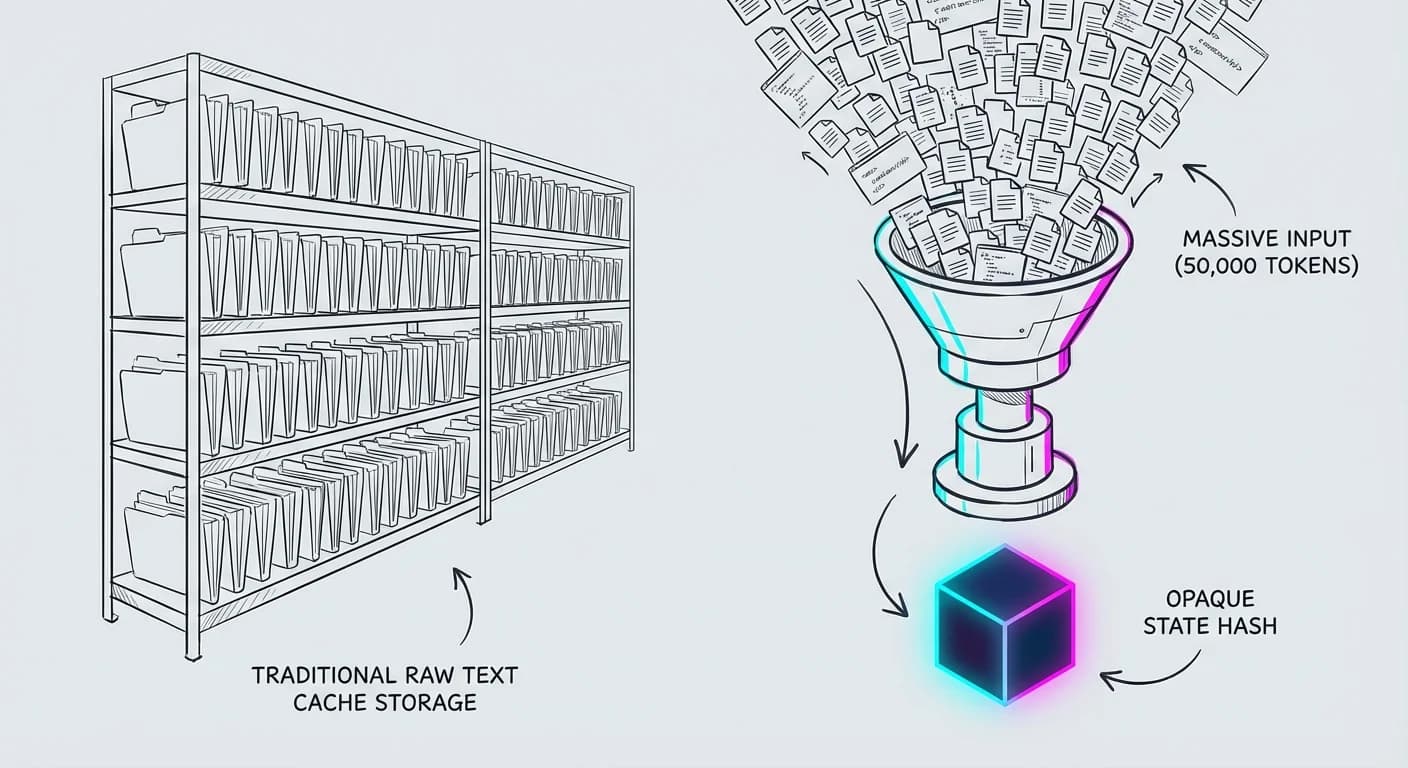
Aquí es donde la cosa se pone interesante. GPT-5.2-Codex no gestiona el contexto largo simplemente "agrandando la memoria RAM". Utiliza una técnica que nosotros llamamos internamente Persistencia de Estado Opaco.
El Mito del Caching vs. Native Compaction
La mayoría de los equipos de ingeniería confunden Caching (guardar el prompt exacto) con lo que hace este modelo. GPT-5.2-Codex utiliza response compaction para comprimir el estado de la conversación.
Imagina esto:
- Entrada: 50 archivos de código fuente (50k tokens).
- Proceso: El modelo "digiere" la estructura semántica.
- Salida Compactada: Un hash/estado opaco que representa ese conocimiento, pesando una fracción del original.
⚠️ El Trade-off Ingenieril: Ganas eficiencia masiva, pero pierdes trazabilidad. Si el modelo alucina basándose en un estado comprimido de hace 4 horas, no puedes hacer "debug" de ese estado porque es ilegible para humanos. Es una caja negra dentro de una caja negra.
El Bucle de Razonamiento (The Agentic Loop)
El modelo no escupe código linealmente. Ejecuta un ciclo de fases que, según la documentación de OpenAI API, soporta niveles de esfuerzo de razonamiento "xhigh". Lo hemos diagramado así:
Cargando diagrama...
Este ciclo permite corregir sus propios errores. Este enfoque "agentic" es lo que le permite abordar desafíos de ciberseguridad defensiva y CTF (Capture The Flag) con una competencia que los modelos anteriores no tenían. No es que sea más inteligente; es que es más terco y tiene herramientas para validar su terquedad.
4. Reality Check: Lo que se rompe en Producción
Dejemos la teoría. ¿Qué pasa cuando conectas esto a un repo real? Hemos analizado la integración en herramientas de Vibe Coding como Cursor y GitHub Copilot para traerte la verdad sin filtros.
La Latencia es el Asesino del Flow
Para tareas complejas con razonamiento alto, el Time-to-First-Token sufre. Si estás acostumbrado a modelos "Instant", esto se siente eterno. La comunidad reporta que su lugar está en tareas asíncronas (background workers) o refactorizaciones profundas, no en el chat interactivo rápido.
La Trampa de los Benchmarks
Ojo al dato: 75.40% en SWE-bench Verified es un hito, pero en la vida real, el código "verificado" a veces es código "spaghetti" que pasa los tests pero es inmantenible.
💡 Insight de la comunidad: El modelo tiende a "sobre-ingenierizar" soluciones simples. Pides una función de una línea y te devuelve una clase con tres interfaces y docstrings de dos párrafos.
Windows por fin existe
Históricamente, los LLMs apestaban en PowerShell y .NET. GPT-5.2-Codex muestra mejoras tangibles en el ecosistema Microsoft y soporte para Windows, algo crítico para el sector Enterprise/Bancario que ha sido ignorado por modelos entrenados puramente en Linux/Cloud.
5. Impacto de Negocio: La Matemática del ROI
Hablemos de dinero. Aunque el pricing exacto varía según el contrato Enterprise, la lógica de eficiencia es clave.
Escenario Real: Refactorización de un Módulo de Autenticación (Legacy)
- Contexto: 50k tokens.
- Salida: 150k tokens (código + tests).
- Iteraciones: 3 (promedio realista).
Comparativa: Un ingeniero Senior cuesta ~$150/hora. Si GPT-5.2-Codex le ahorra 2 horas de trabajo manual tedioso mediante su capacidad de interpretar diagramas técnicos y capturas de pantalla, el ROI es masivo, incluso con costos de API premium.
❌ La trampa: Si usas este modelo para preguntas triviales ("¿cómo centro un div?"), estás quemando dinero. La eficiencia de la compactación ayuda, pero el costo por token de razonamiento sigue siendo alto.
Seguridad: OpenAI lo posiciona para ciberseguridad defensiva, mejorando el análisis de dependencias y rutas de código desconocidas. Úsalo para auditoría asistida, no para reemplazar a tu equipo de Red Teaming.
6. Plan de Acción: ¿Listo para implementar?
No instales esto a ciegas. Aquí está nuestra recomendación táctica:
- Segmenta tus Workflows: Configura tus IDEs (VS Code/Cursor) para usar modelos rápidos (GPT-4o/mini) para autocompletado y reserva GPT-5.2-Codex solo para agentes de refactorización compleja.
- Adopta el "Layered Prompting": No le pidas "construye toda la app". Pide el esqueleto -> luego la lógica -> luego la UI. Las tasas de alucinación bajan drásticamente con este enfoque.
- Habilita el Sandboxing: Por defecto viene bloqueado. Mantenlo así. Si el modelo necesita instalar paquetes npm, haz que pida permiso explícito. La seguridad por diseño no es negociable.
Conclusión
GPT-5.2-Codex es una sierra eléctrica industrial. Corta árboles increíblemente rápido, pero si la tratas como un cuchillo de mantequilla, te vas a hacer daño (y te saldrá caro).
✅ ¿Quieres profundizar? Lee nuestro análisis sobre AgentKit de OpenAI o suscríbete a nuestra Newsletter sobre el futuro de la IA.
GPT-5.2-Codex
Ingeniería de Software
LLM Benchmarks
DevOps
Arquitectura AI
Agentes IA