Loading...

Kimi K2.5: La Arquitectura MoE que Desafía a GPT-4 por $0.60
Última actualización: 1/28/2026
Kimi K2.5: La Arquitectura MoE que Desafía a GPT-4 por $0.60
Por el Equipo PAI
Olvídate de los comunicados de prensa brillantes. Olvídate de los gráficos de barras que siempre suben hacia la derecha. Hoy, en el laboratorio de PAI, hemos abierto el capó de Kimi K2.5, el modelo chino que promete democratizar la IA de frontera.
¿Nuestra misión? Separar la señal del ruido.
El mercado nos vendió una historia: "Rendimiento de GPT-4 en una RTX 4090". La realidad ingenieril es mucho más matizada, fascinante y, honestamente, un poco dolorosa para quien no esté preparado. Si has estado siguiendo la historia de DeepSeek, sabrás que la eficiencia china está cambiando el juego.
Aquí tienes la autopsia técnica completa.
⚡ TL;DR: Resumen Ejecutivo (Para el Manager con Prisa)
| Dimensión | El Veredicto PAI |
|---|---|
| ¿Qué es? | Un monstruo MoE (Mixture-of-Experts) de 1 Billón de parámetros, pero "ligero" en ejecución. |
| La Promesa | Rendimiento que rivaliza con GPT-4 y Claude 3.5 a una fracción del costo. |
| El Ahorro | 75% más barato en tokens de salida que sus competidores directos. |
| El Riesgo | Alucinaciones en modo "enjambre" y latencia impredecible en hardware barato. |
| Ideal para | Generación de código, automatización visual y startups bootstrapping. |
| Evitar en | Casos de uso donde la latencia de <50ms sea crítica (debido al routing del MoE). |
1. Deep Dive Técnico: Diseccionando la Bestia MoE
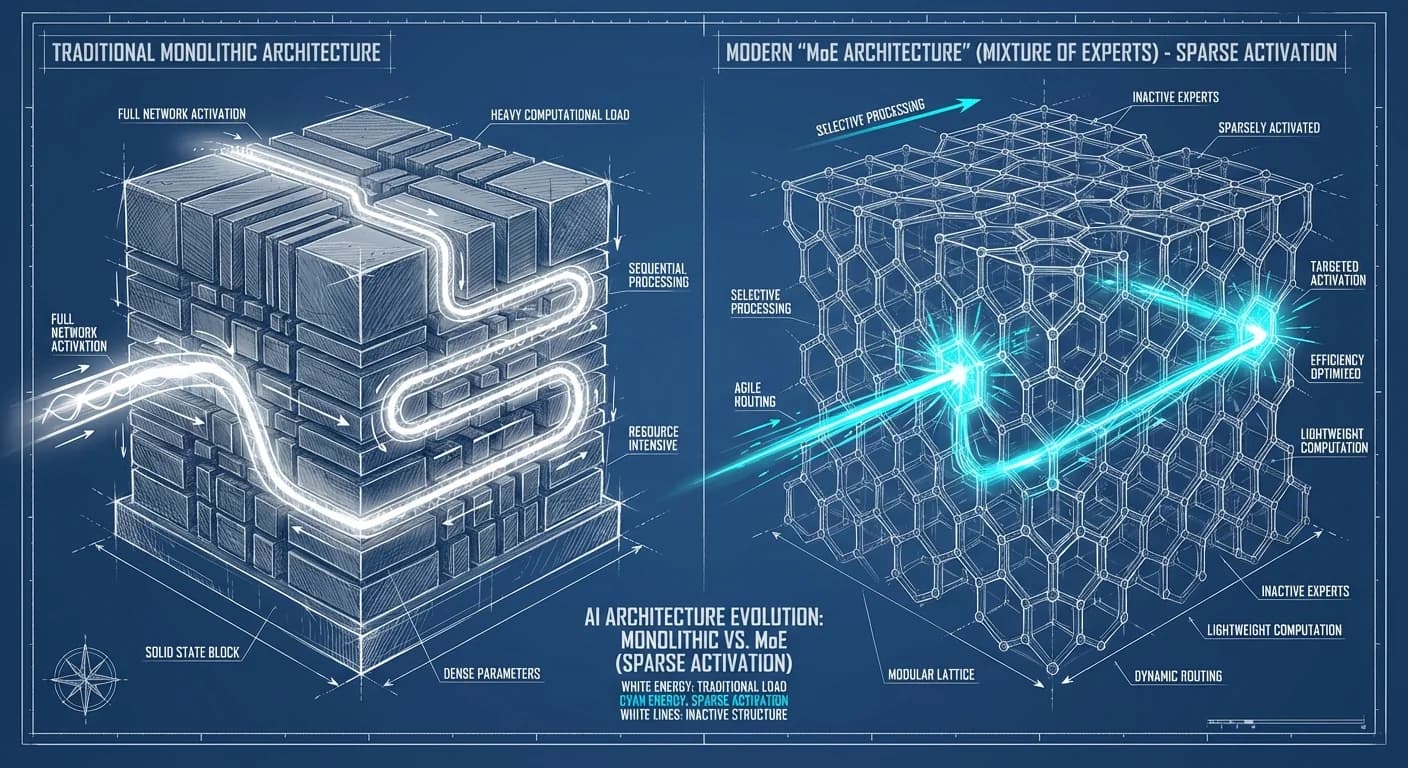
Kimi K2.5 no es un bloque monolítico de neuronas; es una colmena corporativa. Mientras que modelos densos antiguos intentan saberlo todo con cada neurona, Kimi es un edificio con departamentos especializados.
La Arquitectura: Dispersión Controlada
El secreto está en el enrutamiento dinámico. De sus 1 billón de parámetros totales, solo 32 mil millones se activan por token. Esto transforma un problema de cómputo cuadrático en uno lineal, permitiendo una inferencia sorprendentemente ágil para su tamaño total.

Diagrama Conceptual del Gating (Top-2 Router):
Cargando diagrama...
El Código: ¿Cómo decide el modelo?
Bajo el capó, Kimi utiliza un mecanismo de Softmax Top-K para decidir qué expertos despiertan. Aquí un snippet conceptual de cómo funciona este enrutamiento:
python
💡 El Insight Técnico: Esta arquitectura permite que el modelo tenga la "memoria" de un gigante (1T params) pero la "agilidad" de un modelo mediano. Sin embargo, introduce el costo de enrutamiento: el modelo gasta cómputo decidiendo a quién preguntar, lo que puede generar picos de latencia.
2. Reality Check: Lo que Nadie te Cuenta
Aquí es donde se rompe el marketing. Hemos analizado los reportes de campo y la "verdad de la calle".
El Cuello de Botella del Hardware Local
Aunque se promociona como auto-hospedable, ejecutar el modelo completo (incluso cuantizado) requiere una infraestructura seria. No es tan simple como "correrlo en tu laptop".
- El Problema: El modelo usa Memory-Mapped I/O si no cabe en VRAM, paginando pesos desde el SSD.
- El Resultado: Si intentas correr esto en una sola GPU de consumidor sin suficiente VRAM unificada, verás pausas notables (stalls) cuando el modelo cambia de contexto (ej. de hablar de historia a escribir código) y necesita cargar un experto nuevo desde el disco.
La Trampa del "Agent Swarm" (Enjambre de Agentes)
Kimi destaca por su capacidad de enjambre de agentes, descomponiendo tareas complejas en sub-tareas paralelas. Suena genial: 100 agentes trabajando a la vez.
Lo que debes vigilar:
"El modelo maestro a veces se cree las mentiras de sus subordinados."
En flujos de trabajo complejos, como el Agent Chaining y Tool Use, la coordinación de múltiples agentes aumenta la superficie de error. Si un sub-agente alucina, el coordinador puede integrar ese error en la respuesta final. La coherencia global a veces sufre en favor de la velocidad paralela.
3. Impacto de Negocio: ROI y Soberanía
Para el Manager o el CTO, la ecuación cambia drásticamente al mirar los costos y la independencia. Si estás haciendo un análisis para elegir el mejor modelo en 2025, estos números son críticos.
Comparativa de Costos (Por Millón de Tokens)
| Modelo | Input ($) | Output ($) | Ahorro vs GPT-4o (Output) |
|---|---|---|---|
| GPT-4o / Claude 3.5 | ~$2.50 - $5.00 | ~$10.00 - $15.00 | 0% |
| Kimi K2.5 (API) | $0.60 | $2.50 | ~75-80% |
Ventajas Estratégicas
-
Time-to-Market: Kimi brilla en Prototipado Visual. Su capacidad multimodal nativa permite interpretar datos visuales y textuales eficientemente. Puedes pasar de un screenshot de UI a código funcional más rápido que con modelos que no están optimizados para flujos agénticos.
-
Soberanía Tecnológica: Al ser Open Source bajo licencia Apache 2.0, Kimi permite auto-hospedaje total. Esto es crítico para Fintech o Salud en regiones con regulaciones estrictas de datos: tus datos no tienen por qué salir de tu VPC.
4. Plan de Acción: ¿Listo para Implementar?
Desde el Equipo PAI, esta es nuestra recomendación directa:
- Fase de Exploración (Semana 1): No compres hardware todavía. Usa la API para probar si la ventana de contexto de 256k maneja tus documentos legales o técnicos sin perder el hilo.
- El Test de Fuego: Pon a Kimi a refactorizar código o transformar diseños visuales. Si tu equipo de desarrollo sonríe, sigue adelante.
- Producción (La Decisión):
- ¿Necesitas Privacidad Absoluta? Prepara un presupuesto para instancias en Runpod con configuración Llama.cpp o hardware H100/A100.
- ¿Eres una Startup Bootstrap? Usa la API. La relación calidad-precio ($0.60/1M tokens) es imbatible para escalar MVP.
Conclusión
Kimi K2.5 no es perfecto, pero es peligrosamente eficiente. En la guerra de la IA, a veces no necesitas el tanque más grande; necesitas el enjambre más rápido y barato.
✅ Próximos pasos: Si te interesa profundizar en alternativas de bajo costo y alto rendimiento, lee nuestra comparativa sobre DeepSeek vs ChatGPT vs Claude.
Kimi K2.5
Moonshot AI
Mixture of Experts
LLM Open Source
Agentes IA
Desarrollo de Software