Loading...

World Models: Por qué tu IA necesita "Soñar" para Entender la Física
Última actualización: 1/26/2026
World Models: Por qué tu IA necesita "Soñar" para Entender la Física
Resumen Rápido: Los LLMs dominan el lenguaje, pero fallan en el mundo físico. Los World Models son la respuesta: arquitecturas que permiten a la IA simular futuros posibles antes de actuar. Analizamos cómo funcionan, desde la teoría de Ha & Schmidhuber hasta los avances de Genie 3 y la robótica humanoide.
1. El Gancho: Cuando los LLMs Chocan con la Pared (Literalmente)
Hemos pasado los últimos dos años obsesionados con que la IA "hable" bien. Pero si le pides a un LLM que conduzca un coche o apile cajas en un almacén, nos topamos con un muro de realidad:
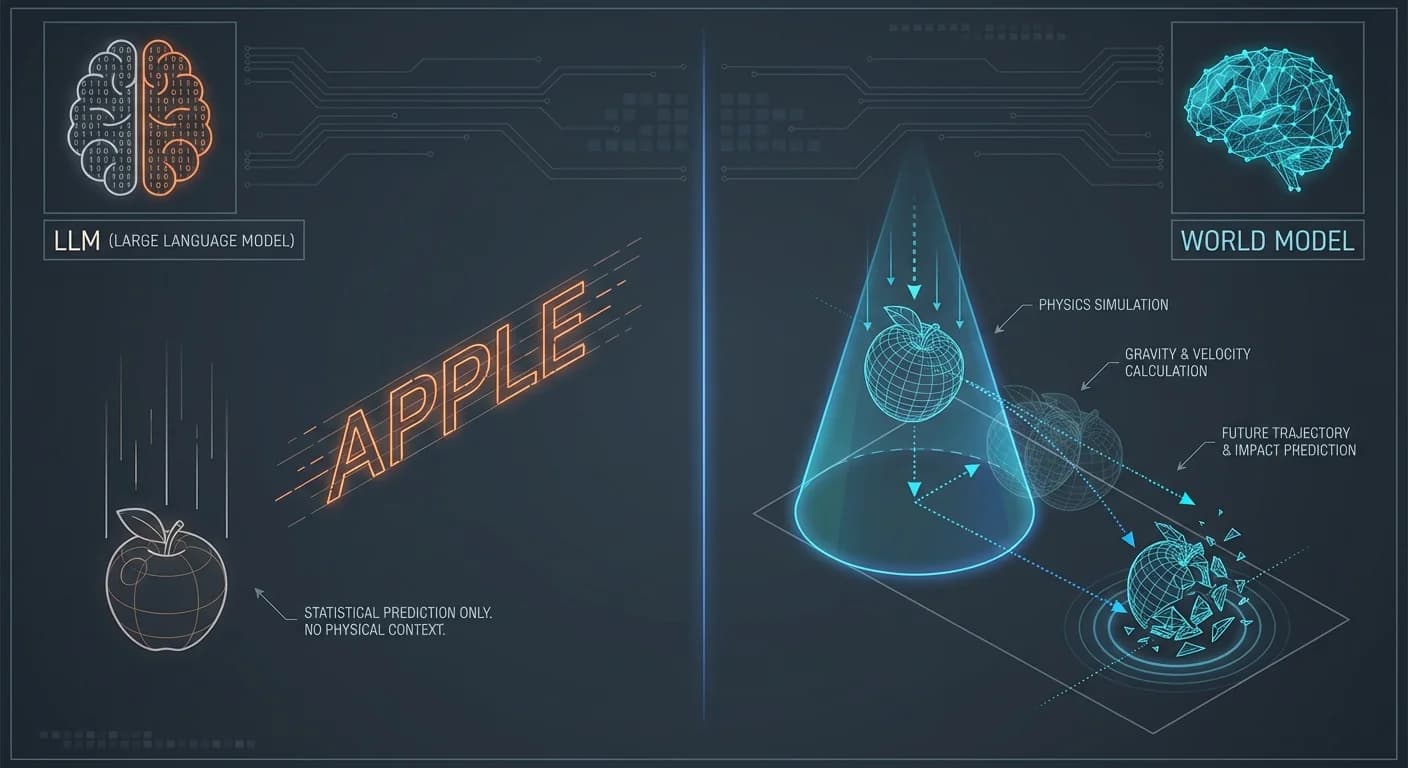
Las palabras no tienen física.
Aquí es donde entran los World Models. Si los LLMs son el área de Broca (lenguaje), los World Models son el córtex visual y motor: redes neuronales que entienden la dinámica del mundo real, permitiendo a una máquina cerrar los ojos, imaginar una acción y predecir sus consecuencias antes de ejecutarla.
En el laboratorio de PAI hemos estado diseccionando la última ola de papers (Genie de Google, DreamerV4, JEPA) y la conclusión es clara:
Esta es la pieza que falta para la verdadera IA Agente.
2. TL;DR: Resumen Ejecutivo (Para el CTO con Prisa)
💡 ¿Qué es? Una arquitectura que construye una representación interna del entorno para simular futuros. No aprende por "prueba y error" en la realidad, sino "soñando" escenarios en una simulación latente.
💰 ¿El ROI Inmediato? Eficiencia de Muestreo Masiva. Entrenar un robot en el mundo real es lento, caro y peligroso. Con un World Model, el agente aprende en segundos de simulación lo que tardaría años en realidad.
🚀 Estado del Arte: Genie 3 de Google DeepMind (entornos interactivos generales), Tesla (FSD) y 1X Technologies (Robótica humanoide).
⚠️ La Advertencia: Sufren de "alucinaciones físicas" a largo plazo y requieren cantidades masivas de video para pre-entrenar. No es magia, es estadística predictiva aplicada a la física.
3. Deep Dive Técnico: Diseccionando la Máquina de Sueños
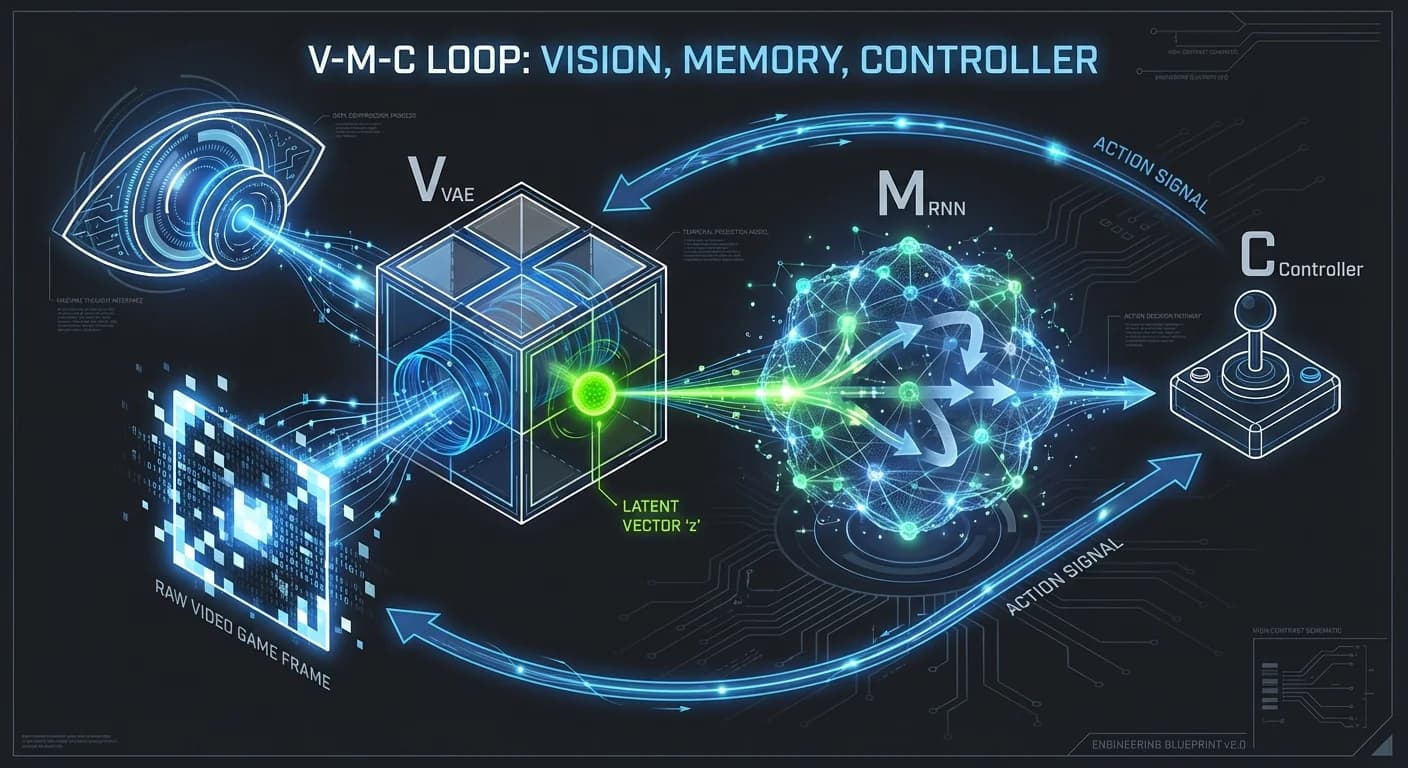
Olvídate del marketing. A nivel de ingeniería, un World Model no es una caja negra monolítica; es un bucle de tres componentes críticos. Basándonos en la arquitectura canónica de Ha & Schmidhuber (2018) y sus evoluciones modernas, así es como funciona bajo el capó:
La Tríada Arquitectónica (V-M-C)
🔄 Flujo de Datos: Input -> VAE (z) -> RNN/Transformer (h) -> Controller (a) -> Environment
1. Modelo de Visión (V) - El Compresor
El mundo es demasiado ruidoso (píxeles crudos). El modelo no puede procesar 4K en tiempo real. Usamos un VAE (Variational Autoencoder) o Tokenizadores Discretos.
- Input: Frame de video (x_t).
- Output: Un vector latente comprimido (z_t).
- Insight: Aquí se descarta la información irrelevante (el color de la pared) para quedarse con lo vital (la velocidad del objeto).
2. Modelo de Memoria/Dinámicas (M) - El Simulador
Este es el corazón. Históricamente una RNN (LSTM), hoy evolucionando hacia Transformers Espacio-Temporales.
latex
- Traducción: Dado el estado actual y mi acción (a_t), ¿cuál es el siguiente estado?
- Código Mental: Es un motor de física aprendido, no programado.
3. Controlador (C) - El Agente
Típicamente una red neuronal simple (MLP). Como el Modelo (M) hace el trabajo pesado de entender la causalidad, el Controlador puede ser ligero.
- Tarea: Maximizar la recompensa esperada dentro de la simulación del Modelo (M).
El Debate del Momento: ¿Píxeles o Conceptos?
Aquí hay una guerra civil académica interesante:
-
El Enfoque Generativo (Sora, Genie): Intentan predecir el siguiente píxel. Se ven increíbles visualmente, pero es computacionalmente carísimo y propenso a errores visuales que no afectan la lógica. Puedes leer más sobre modelos avanzados en nuestro análisis de Gemini 3.
-
El Enfoque JEPA (Yann LeCun): Argumenta que predecir píxeles es ineficiente. Su arquitectura predice en el espacio latente abstracto.
💡 The Lightbulb Moment: Si llueve en la simulación, no necesitas predecir la posición de cada gota de agua (píxeles), solo necesitas saber que "el suelo está resbaladizo" (estado latente).
4. Reality Check: Lo que Nadie te Cuenta
Hemos revisado los foros y los benchmarks (sí, leemos los comentarios en OpenReview) para traerte la realidad sucia.
El Problema de la "Miopía Temporal" (Compounding Errors)
Esto es lo que mata a los proyectos en producción. Los World Models son autoregresivos. Si el modelo tiene un error del 1% en el frame t+1, ese error se alimenta para predecir t+2. Para el frame t+100, tu simulación es basura.
- Dato: Aunque Genie 3 logra coherencia por minutos, versiones anteriores colapsaban en segundos. Para un coche autónomo, la estabilidad a largo plazo es no negociable.
La "Brecha de Realidad" (Reality Gap)
Un robot entrenado en un World Model se vuelve experto en... explotar los bugs del World Model.
❌ El Anti-Pattern: Un agente en simulación puede aprender que vibrar a alta frecuencia le permite atravesar paredes debido a errores de punto flotante. En la vida real, el robot simplemente se rompe los motores.
Esto requiere técnicas de Domain Randomization para mitigarse.
5. Impacto de Negocio: ¿Dónde está el Dinero?
Si eres Manager, olvida la física cuántica y mira estos tres verticales donde la inversión está fluyendo:
1. Vehículos Autónomos (La Ballena Blanca)
Wayve y Tesla están apostando todo aquí. El valor no es solo conducir, es la generación de datos sintéticos. Pueden simular millones de "casos borde" (un niño saltando detrás de un camión) que rara vez ocurren en la realidad, pero que son críticos para la certificación.
2. Robótica Generalista (1X, Amazon)
El modelo 1XWM demuestra que se puede pre-entrenar con videos de YouTube y hacer fine-tuning en robots. Esto reduce el Time-to-Market de nuevos comportamientos robóticos drásticamente.
3. Seguridad Predictiva
En lugar de detectar un accidente cuando ocurre, un World Model puede analizar el video en tiempo real y predecir: "Esa carretilla elevadora va a chocar en 3 segundos". Prevención vs. Reacción.
6. Plan de Acción: ¿Cómo Empezar?
No intentes entrenar un World Model desde cero (a menos que tengas el presupuesto de computación de Google). Aquí está nuestra ruta recomendada:
-
Nivel Principiante (Exploración): Descarga el repo de DreamerV3. Funciona en una sola GPU y corre en entornos de Atari/Minecraft. Es la mejor forma de entender el ciclo V-M-C sin gastar una fortuna en nube.
-
Nivel Intermedio (Ingeniería): Usa NVIDIA Isaac Sim. Aunque no es un World Model neuronal puro (es híbrido con física tradicional), es el estándar industrial para simulación robótica hoy.
-
Nivel Avanzado (I+D): Experimenta con arquitecturas híbridas: Usa un LLM para la planificación de alto nivel ("Coge la caja roja") y un World Model pequeño para la ejecución motora ("Mover brazo 10cm").
Conclusión del Equipo
Los World Models son la transición de una IA que "observa" a una IA que "entiende". La tecnología es inmadura y costosa, pero es el único camino viable hacia agentes autónomos reales.
El que domine la simulación, dominará la realidad.
✅ ¿Quieres profundizar? Lee nuestra comparativa sobre Aprendizaje por Refuerzo vs LLMs para entender el futuro de los agentes.
World Models
Reinforcement Learning
Genie
DreamerV3
Robótica
Agentes Autónomos