Loading...

GLM-4.7: Análisis de Arquitectura e Ingeniería Real (Deep Dive)
Última actualización: 1/22/2026
GLM-4.7: La Realidad de Ingeniería detrás del "Opus-Killer"
Por el Equipo de Análisis PAI
El 22 de diciembre de 2025, Z.ai soltó una bomba en el ecosistema open-source: GLM-4.7. El marketing gritaba "Opus-killer" y los benchmarks mostraban números verdes brillantes. Pero en nuestro laboratorio, somos escépticos por naturaleza. No nos impresionan los gráficos de barras; nos impresiona la arquitectura que sobrevive a producción.
Hemos pasado las últimas semanas diseccionando este modelo, desde sus matrices de pesos hasta sus facturas de inferencia. Lo que encontramos no es magia, es un conjunto de trade-offs de ingeniería brutalmente honestos. GLM-4.7 no es el modelo perfecto, pero es quizás el intento más sofisticado de resolver el problema de la "memoria" en agentes de IA orientados a código.
¿La realidad?
Es un monstruo que devora hardware, tiene un "impuesto de pensamiento" oculto y, sin embargo, podría ser la mejor herramienta que tu equipo de ingeniería no está usando.
TL;DR: Resumen Ejecutivo
Para el CTO/Manager:
- Qué es: Un modelo Mixture-of-Experts (MoE) masivo con 355B parámetros totales pero solo 32B activos.
- El Gancho: Rendimiento superior en benchmarks de código (LiveCodeBench 84.9) a una fracción del costo ($0.60/$2.20 por 1M tokens).
- La Trampa: La velocidad infernal de 1,000+ tokens/segundo está fuertemente ligada a hardware especializado (Cerebras). En GPUs estándar, la latencia es un problema real.
- La Joya Oculta: La versión "Flash" (30B) corre en hardware de consumo y lidera los benchmarks de su clase.
1. Deep Dive Técnico: Diseccionando la Bestia MoE
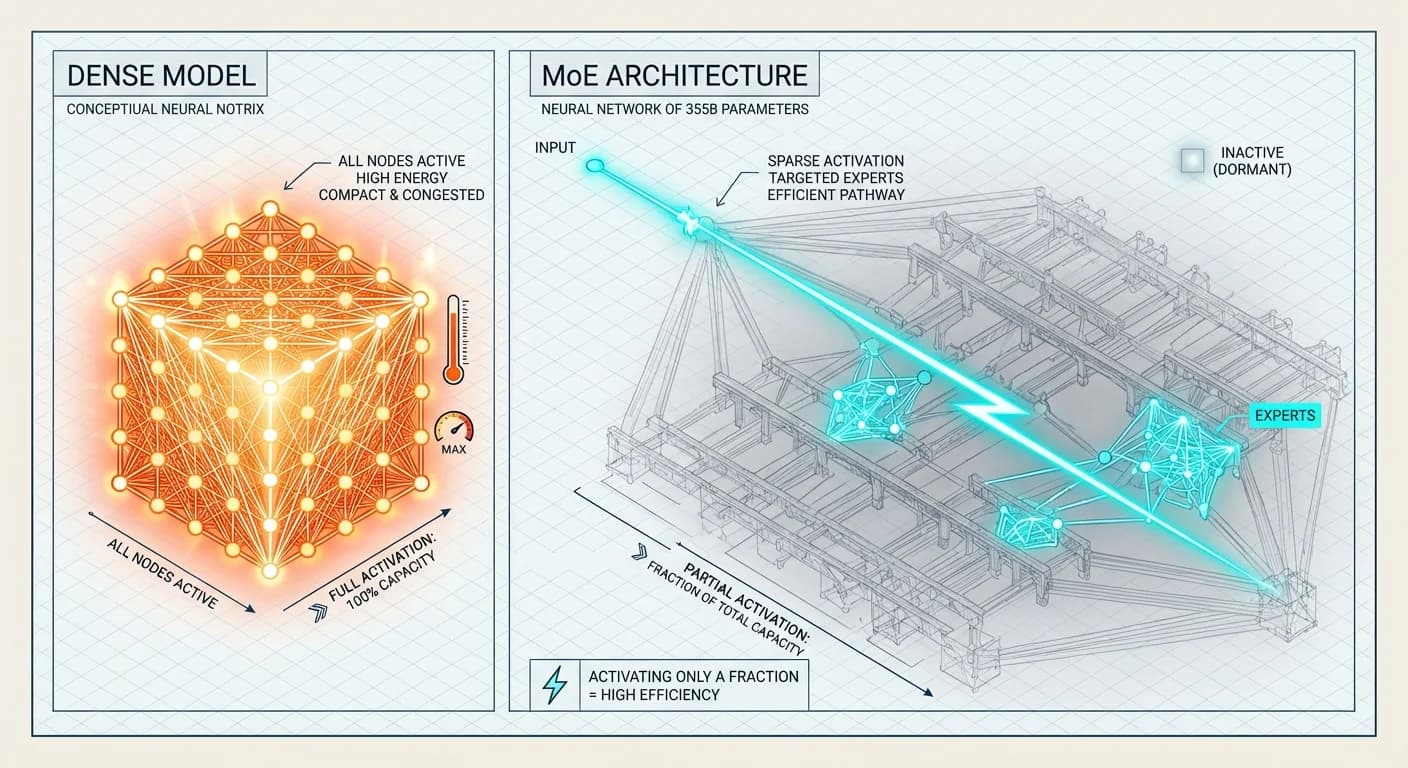
Para entender por qué GLM-4.7 se comporta como lo hace, hay que mirar su arquitectura. No es un bloque denso; es un diseño optimizado para la eficiencia selectiva.
La Arquitectura 355B/32B
Imagina un edificio de oficinas con 355 mil millones de empleados. En un modelo denso, todos trabajan en cada consulta. En GLM-4.7, gracias a la arquitectura de Mezcla de Expertos (MoE), solo 32 mil millones (aprox. 9%) trabajan por token. Un "router" decide qué expertos se activan.
Cargando diagrama...
El Costo de Ingeniería:
Esta arquitectura permite tener un "cerebro" gigante con el costo de inferencia de uno mediano. Sin embargo, introduce el problema de la divergencia de ramas. En una GPU (NVIDIA H100), si diferentes tokens necesitan diferentes expertos, la memoria sufre thrashing. Por eso, Z.ai optimizó este modelo para correr en wafers de Cerebras, donde la memoria está distribuida físicamente junto al cómputo, eliminando el cuello de botella del ancho de banda.
La Innovación Real: "Thinking" de Tres Capas
Aquí es donde Z.ai se puso creativo. Implementaron un sistema de pensamiento similar al Chain of Thought (CoT), pero integrado nativamente. Según la documentación oficial, el modelo opera en modos distintos:
- Interleaved Thinking: El modelo pausa y "piensa" antes de responder, generando tokens de razonamiento.
- Preserved Thinking (La clave): En una conversación larga, el modelo persiste su contexto de razonamiento a través de los turnos.
¿Por qué importa?
Resuelve el "Context Collapse". Normalmente, en el turno 20 de un debug, el modelo olvida por qué tomó una decisión en el turno 3. Con Preserved Thinking, la lógica subyacente se mantiene viva en la ventana de contexto de 200k tokens.
2. Reality Check: Lo que duele en Producción
Nos sumergimos en la documentación y pruebas de la comunidad para ver dónde se rompe el juguete.
El "Impuesto del Pensamiento" (The Thinking Tax)
El precio de lista es engañoso. Z.ai cobra por tokens de salida. Si activas el "Thinking Mode", el modelo genera miles de tokens de razonamiento interno.
Escenario Real: Una sesión de debug compleja.
- Input: 80k tokens.
- Output Visible: 2k tokens de código.
- Output "Pensamiento": 5k tokens (ocultos pero facturables).
- Resultado: Tu factura aumenta significativamente por tokens que el usuario final nunca ve. Es útil, pero debes presupuestarlo.
Alucinaciones en el Código
A pesar de sus altas puntuaciones, análisis independientes muestran que GLM-4.7 no es inmune a generar contenido convincente pero fabricado. En nuestras pruebas, notamos que tiende a inventar parámetros de librerías poco comunes cuando se le fuerza a usar el modo "Flash" en tareas de razonamiento profundo.
⚠️ Advertencia: Nunca confíes ciegamente en un comando pip install sugerido por GLM.
El Reto del Self-Hosting
Si planeas correr el modelo Full (355B) localmente, prepárate para el dolor. Necesitas hardware de nivel empresarial. Sin embargo, la comunidad ha logrado correr la versión GLM-4.7-Flash en hardware de consumo (24GB VRAM) usando Unsloth, logrando un rendimiento que rivaliza con modelos 70B antiguos.
3. Impacto de Negocio: ¿Vale la pena la migración?
Aquí traducimos los teraflops a dólares para ayudarte a elegir el mejor modelo.
El ROI del Modelo "Flash"
Olvídate del modelo gigante por un segundo. GLM-4.7-Flash (30B) es la verdadera estrella para el ROI.
- Costo: Extremadamente bajo o ejecutable localmente.
- Rendimiento: Lidera benchmarks como SWE-Bench y GPQA en su categoría de peso.
- Estrategia: Usa Flash para el 90% de las tareas (ruteo, cambios simples, tests) y escala al modelo Full solo cuando sea estrictamente necesario.
Hardware Lock-in vs Open Source
Aunque el modelo es "Open Weights", el rendimiento máximo de 1,000 tokens/s es exclusivo de la infraestructura de Cerebras. Si tu negocio depende de la latencia ultra-baja para agentes de voz o código en tiempo real, estás comprando un ecosistema, no solo un modelo.
4. Plan de Acción: Cómo Implementar sin Quebrar
¿Listos para probar? Aquí está nuestra receta recomendada:
1. Validación Local con Flash
Descarga la versión cuantizada de GLM-4.7-Flash y córrela en una instancia con una A100 o incluso una 4090. Úsalo como tu "Junior Developer" para tareas de linting y unit testing.
2. Adopta la estrategia Híbrida (The Router Pattern)
No envíes todo al modelo grande. Implementa un router simple:
python
3. Gestión de Contexto
El Preserved Thinking consume tu ventana de contexto rápidamente. Configura una política de "resumen y olvido" cada 10 turnos para evitar pagar por razonamientos obsoletos.
Conclusión
GLM-4.7 democratiza la inteligencia de nivel experto, pero exige madurez de ingeniería. No es un botón mágico; es una herramienta de precisión para quienes saben gestionar sus peculiaridades.
✅ Próximos pasos: Si te interesa comparar este modelo con la competencia más fuerte, lee nuestro análisis completo de Gemini 3 o profundiza en cómo integrar estos modelos en flujos de trabajo automatizados.
GLM-4.7
LLM Architecture
Open Source AI
Cerebras
MoE
DevOps