Loading...

Inside Seedance 2.0: The End of "Slot Machine" AI Video?
Last update: 2/16/2026
Inside Seedance 2.0: The End of "Slot Machine" AI Video?
We have all been there. You type a prompt into an AI video generator, burn $2.00 worth of compute credits, and pray. It’s the "Slot Machine" era of Generative Video—where getting a usable clip feels like hitting a jackpot rather than executing a workflow.
But earlier this month, ByteDance (the parent company of TikTok) officially launched Seedance 2.0. They are making a bold claim: they have killed the slot machine. With a reported 90% usable output rate (compared to the industry average of ~20%), they aren't just launching a model; they are attempting to fix the unit economics of AI video production.
Today, the PAI Team is taking you inside the architecture. We are stripping away the marketing fluff to analyze the Dual-Branch Diffusion Transformers, the controversial IP implications that have Hollywood lawyers sharpening their knives, and the real-world trade-offs for your engineering stack.
TL;DR: The Manager’s Cheat Sheet
- The Breakthrough: Seedance 2.0 moves from "prompting" to "directing" via a multimodal reference system. It utilizes a Dual-Branch Diffusion Transformer to generate audio and video simultaneously.
- The Architecture: Unlike competitors that generate video then dub audio (causing sync issues), this architecture processes spatiotemporal tokens and waveform tokens in parallel.
- The ROI: ByteDance claims an 80% reduction in wasted compute. At ~$0.50 per generation vs. competitors at $1.00–$2.50, the cost efficiency is undeniable for high-volume workflows.
- The Red Flag: Massive copyright friction. Disney and Paramount have already sent cease-and-desist letters. Use with extreme caution for commercial public-facing assets.
1. Deep Dive: The Dual-Branch Architecture
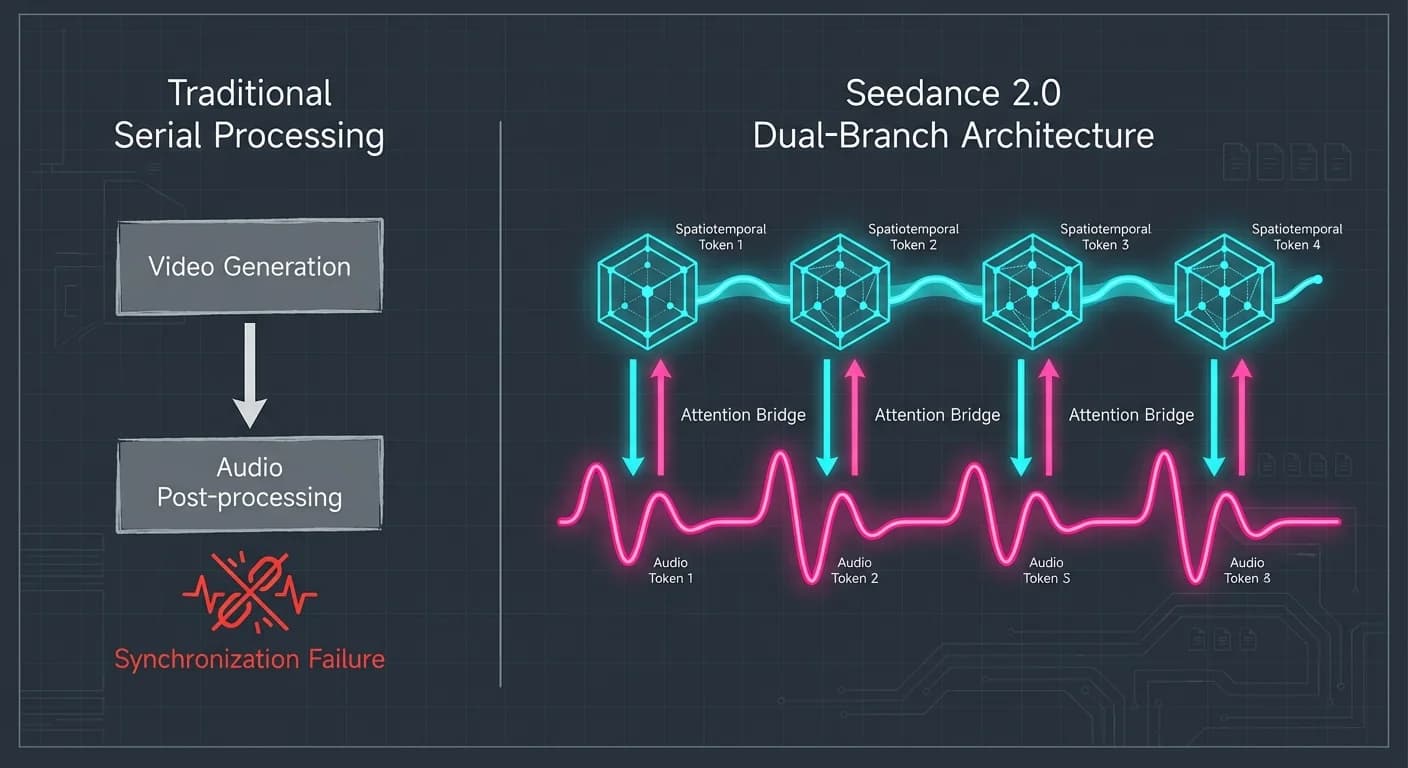
Most current video models (like earlier iterations of Sora or Runway) treat video generation as a stateless, visual-first operation. Audio is often an afterthought—a post-processing layer that tries to "catch up" to the pixels. This is why you see lips moving 200ms after the word is spoken.
Seedance 2.0 flips this via Joint Audio-Visual Generation.
The Mechanics: Two Branches, One Brain
We analyzed the technical documentation and found that Seedance utilizes a Dual-Branch Diffusion Transformer. Imagine two musicians playing in separate rooms, connected only by a window. In Seedance 2.0, that window is the "Attention Bridge."
- Visual Branch: Processes spatiotemporal tokens (3D patches capturing motion/pixels).
- Audio Branch: Processes waveform tokens (spectral features).
- The Bridge: A specialized transformer layer that passes metadata between these branches at the millisecond level during the diffusion process.
This allows for exceptional motion stability and audio-video joint generation. If the Visual Branch generates an explosion, it signals intensity and timing to the Audio Branch. If the Audio Branch generates a melancholic cello swell, it signals pacing and lighting mood to the Visual Branch.
The result? Synchronization tolerances under 40ms.
Cargando diagrama...
2. The "@ Reference" System: Object-Oriented Creativity
This is the feature that developers in our circle are obsessing over. Instead of vague adjectives ("make it cinematic"), Seedance accepts up to 12 reference files (9 images, 3 videos, 3 audio clips).
It functions like an object-oriented programming syntax for creativity. You aren't asking the model to hallucinate a style; you are passing it a pointer to a specific latent representation.
When you prompt:
"@Image1 as character, @Video1 motion reference"
The model extracts the camera trajectory vectors from Video 1 and applies them to the character features of Image 1. It is decoupling content from motion—a massive leap in control that Higgsfield calls "production-ready".
3. Reality Check: The "90% Usability" Myth
Let’s be honest. Marketing metrics are often "best-case scenario" benchmarks. We dug into community feedback to see if the "90% usable output" claim holds water.
The Good
- Simple Scenarios: For standard clips (talking heads, product b-roll), the success rate is indeed high. The Narrative Planning Module acts like an automated storyboarder, breaking prompts into coherent shots automatically.
The Bad (Where it breaks)
- The "Physics Wall": While Seedance excels at camera movement, it struggles with complex physical interactions. Community tests show that multi-character sports scenes or complex fluid dynamics often revert to hallucinations. Comparisons with Sora 2 and Veo 3.1 show it still lags behind OpenAI in raw physics simulation.
- The "Mastery Flat Spot": The "@ reference" system raises the skill floor. Users expecting one-click magic are disappointed. You need to curate high-quality reference assets to get that 90% success rate.
4. The Elephant in the Room: Copyright & The "Safeguard" Failure
We cannot discuss the engineering without addressing the legal firestorm. Within 48 hours of launch, the Motion Picture Association issued cease-and-desist letters, claiming unauthorized use of U.S. copyrighted works on a massive scale.
The Technical Failure of Safeguarding: It appears Seedance 2.0 has severely "overfitted" on copyrighted content. Users found that simple prompts could generate near-perfect replicas of IP characters without "jailbreaking."
From an engineering perspective, this suggests ByteDance prioritized model performance over dataset sanitization. While they have promised to improve IP safeguards, the architectural reality is that once a model has learned the latent representation of a specific character, filtering it out post-training is a game of whack-a-mole. For enterprise users, this is a critical risk.
5. Impact on Business: The Unit Economics War
Despite the legal drama, the economic pressure Seedance 2.0 puts on the market is undeniable. Let's look at the "Cost per Usable Second" based on current pricing models:
- OpenAI Sora 2: ~$1.00+ per generation. (Strengths: Physics, Simulation).
- Google Veo 3.1: ~$2.50 per generation. (Strengths: Broadcast Quality).
- Seedance 2.0: ~$0.50 per generation. (Strengths: Workflow, Control).
The Verdict: Seedance is undercutting the market by 3-5x. For an ad agency producing 500 social media variants a week, this price difference shifts AI video from a "special project" budget to an "operational" budget.
6. Plan of Action: Should You Integrate?
So, is Seedance 2.0 ready for your production pipeline? Here is our take.
✅ GREEN LIGHT (Adopt Now)
- Internal Storyboarding: Use the narrative planner to visualize scripts cheaply.
- Social Media Content: If you need rapid, high-volume video where "perfect physics" matters less than "vibes" and audio sync.
- Style Transfer Workflows: If you have a specific visual style (reference images) you need to animate.
❌ RED LIGHT (Wait/Avoid)
- Broadcast/Cinema: The resolution and physics aren't there yet.
- Commercial IP Assets: Until the copyright safeguards are architecturally robust, the legal risk for major brands is too high.
Final Thought: Seedance 2.0 isn't the "perfect" video model, but it might be the first "programmable" one. By giving us the @ system, ByteDance has admitted that prompts aren't enough—we need handles, references, and controls.
Seedance 2.0
ByteDance
AI Video Architecture
Diffusion Transformers
Generative AI
Tech Strategy